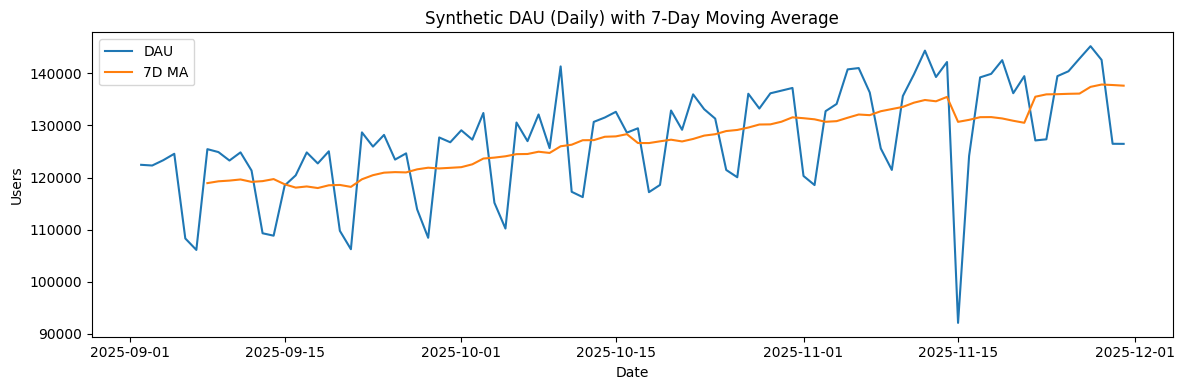
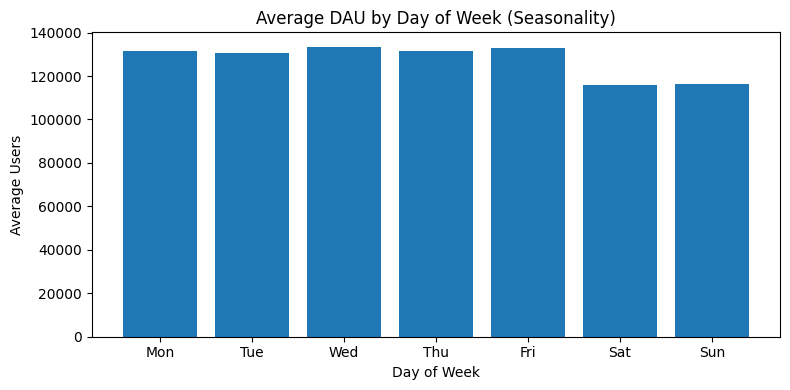
2025-09-01부터 2025-12-01까지 DAU와 7일 이동평균 DAU가 있다. ( 샘플 데이터 )
이 차트를 보고 트래픽이 견조한지, 운영상 이슈는 없었는지 , 앞으로의 과제는 무엇이며 어떻게 개선할 수 있을지 종합적으로 살펴보자.
차트 분석을 먼저 진행하고 이를 기반으로 최종 보고서를 작성하는 것으로 포스팅을 구성한다.
차트 분석
Q1. 추세(Trend): 7D MA 기준으로 전체 기간(약 9~11월) DAU는 상승/하락/횡보 중 무엇인가?
A1. 전체 기간 상승중이다. DAU 기준 , 9월 초 11만명 후반대에서 11월 말 12만명 후반대까지 약 만명의 AU가 증가하였다. ( 약 10% 증가 ) 7D MA 차트로 보면 더 명확하게 전체 기간 상승중임을 알 수 있다.
다만 11월 15일의 급격한 수치 하락으로 7D MA가 크게 감소하는데 DAU로 봤을때는 다음날부터 정상 AU 수준을 회복한다.
이동평균은 노이즈를 줄이는 대신 윈도우 때문에 충격이 며칠간 남는 특성이 있다. 이동평균을 볼때 DAU를 보조 지표로 같이 봐야겠다.
Q2. 계절성(Seasonality): 요일 패턴이 보이는가? 어떤 요일이 강하고 약한가?
A2. 2번째 차트 (Average DAU by Day of Week)를 봤을때 주말에 트래픽이 빠지는것을 알수있다. 거의 모든 주간에서 주말에 트래픽이 빠졌다가 주중에 회복되는 경향을 보인다. 주말에 트래픽이 빠지는 것이 유사한 수준으로 주기성을 보이는지 체크해봐야한다.
주기성있게 주말에 유사한 수준의 트래픽이 빠지는 것이라면 정상 패턴으로 고려할 수 있다. Weekly weekday vs weekend 차트를 통해 주말도 우상향하고있는지 보면 주말이 문제인지 정상 패턴인지 구분할 수 있다.
Q3. 이상치(Anomaly): 그래프에서 비정상적으로 튀는 날이 보이는가? 그 날짜 전후로 어떤 형태(급락/급등/회복)를 보이는가?
A3. 2025-10-10 , 2025-11-15 이 두지점이 눈에 띈다.
먼저 2025-10-10일(금요일)은 9월부터 10월중 유일하게 DAU 14만명을 찍었다. 주말을 제외하고 평일중 전일 대비 가장 많이 증가한 날이다. 직전 금요일 (10/03) 대비해서도 6.75% 증가하였다. 다만 바로 다음날 트래픽이 빠져서 증가를 유지하진 못했다.
2025-11-15은 최저 트래픽을 기록한 날이며 전일 대비 가장 많이 감소한날이다. 평소에도 주말에 하락폭을 보이긴하지만 가장 큰 폭으로 트래픽이 감소하였다. 전일 대비 약 5만명이 빠졌는데 이는 35.2% 감소한 수치이다. 직전 토요일 (11/08) 대비로는 -26.6% 감소, 토요일 평균 (약 115,692명) 대비로 봐도 꽤 이례적으로 감소한 수치이다.
전일 대비와 함께 동요일 대비도 같이봐야 증감 효과를 명확하게 파악할 수 있다. 전일 대비로만 볼 경우 주말 효과가 섞일 수 있다. ( ex. 금->토 )
장시간 점검이 있었을 가능성이 높다.(접속 불가) 로그인 실패/서버 에러율/크래시율/점검 공지 시간대 매칭을 통해 큰 이슈는 아닐지 체크해봐야한다.
추가로 잔차에서 이상치를 잡는 STL decomposition 같은 방법을 쓰면 요일 효과를 깔끔히 걷어내고 이상치를 판단할 수 있다.
STL(Seasonal-Trend decomposition using LOESS) decomposition :
시계열 데이터를 관측치 = 추세(Trend) + 시즌(Seasonal) + 잔차(Residual) 로 분해하는 방법.
주간(요일)처럼 강한 주기 패턴이 있을 때, 주기성을 걷어내고도 남는 설명되지 않는 충격(Residual)을
분리해 이상치를 더 공정하게 잡는 데 유용.
Q4. 운영 관점 가설과 액션 플랜을 제시하라: 예: 이벤트/마케팅, 점검/장애, 콘텐츠 업데이트, 외부 이슈(연휴 등) 와 다음 액션(데이터 추가 확인)
A4. 주말 트래픽 하락을 보완하는 것이 가장 큰 과제이다. 트래픽 하락의 유형을 먼저 나눠서 살펴본 후 다른 지표에 영향은 없었는지 이를 끌어올리려면 어떻게 해야할지 살펴보자.
DAU를 신규/복귀/기존(연속) 활성으로 분해 (주말에 무엇이 빠지는지 바로 보임)
리텐션/코호트: 주말 포함 코호트 vs 주말 제외 코호트 비교 (주말이 이탈 트리거인지 확인)
세션/플레이타임/핵심행동(던전 클리어, 매칭, 결제 등) 동반 하락 여부 => 주말에 빠지는 유저층이 누군지 규명하고 이 유저들이 주말에도 접속하게 만드는 방법을 찾자.
ex)
CASE 1) 평일에 신규 유저가 가입하고 주말에 바로 빠짐. 신규 유저는 지속 증가 => 신규 유저들이 이탈하지않도록 보상 설계 : ex) 14일 연속 출석 이벤트. 주말마다 큰 보상
CASE 2) 복귀 유저가 바로 이탈하고 새로운 복귀 유저 들어오는 회전문 형태의 유입 => 복귀 유저 잔존하도록 이벤트 설계 ex) 연속 리텐션 보상 확대
CASE 3) 평일에 복귀했던 유저가 주말에 빠졌다가 평일에 다시 들어오는지 ( 평일 컨텐츠만 즐김 ) => 평일에만 플레이하는 유저가 주말에도 플레이하도록 만들기 ex) 평일 던전 -> 주말 던전으로 확장
최종 보고서
1. 목적 & 지표 정의
목적
9~11월 DAU의 추세 확인
요일 효과 정량화 ( seasonality )
이상치(급등/급락)를 요일 효과와 분리해 탐지하고 운영 액션으로 연결
지표 정의
DAU : 특정 날짜에 앱/서비스에 활동한 고유 사용자 수
7D Moving Average(7D MA): 단기 변동을 완화해 추세를 더 잘 보이게 하는 스무딩 기법
2. 핵심 KPI 요약
전체 추세 : 7D MA 기준 +15.7% 상승 (기간 초반 ≈ 118,930 → 기간 말 ≈ 137,626)
요일 효과 (주말 효과) :
평일 평균(Mon–Fri) ≈ 131,921
주말 평균(Sat–Sun) ≈ 116,028
주말/평일 비율 ≈ 0.880 → 주말이 평일 대비 약 12% 낮음
주요 이상치 후보(시각화에서 점으로 표시)
2025-10-10 급등
2025-11-15 급락(최저치)
3. 시각화 기반 인사이트
추세(Trend) : 상승
7D MA와 STL Trend 모두 완만한 우상향.
운영 해석: 기본 체력(베이스)이 상승 중이므로, 단기 변동(요일/이벤트/장애)을 분리해 관리하면 성장 해석이 깔끔해짐.
주기성 (Seasonality) : 주말 약세가 구조적으로 반복
요일 패턴이 반복되며, 주말에 일관되게 떨어졌다가 주중에 회복.
운영 해석: “주말 하락”이 정상 패턴 범위인지, 혹은 최근에 더 약해지는지(악화)가 핵심 포인트
이상치(Anomaly) : STL decomposition 으로 요일 효과 제거 후 확인
STL residual 차트에서 11/15는 매우 큰 음의 잔차(급락), 10/10은 양의 잔차(급등)로 관측.
주말이라 원래 낮다 같은 요일효과를 걷어낸 뒤에도 설명되지 않는 충격이 남아 이상치 가능성이 높음
Residual z-score 기반 탐지(ㅣzㅣ ≥ 3)로 요일효과 제거 후에도 남는 충격을 이상치 후보로 표시
날짜
DAU
7D MA
STL Trend
STL Seasonal
STL Residual
z
2025-10-10
141,321
125,998
125,338
+2,458
+13,525
+3.26
2025-11-15
92,118
130,686
136,530
-10,007
-34,405
-7.99
STL(Seasonal-Trend decomposition using LOESS) decomposition :
시계열 데이터를 관측치 = 추세(Trend) + 시즌(Seasonal) + 잔차(Residual) 로 분해하는 방법.
주간(요일)처럼 강한 주기 패턴이 있을 때, 주기성을 걷어내고도 남는 설명되지 않는 충격(Residual)을
분리해 이상치를 더 공정하게 잡는 데 유용.
적용 방식 (보고서 기준):
period=7(주간), robust=True로 분해
Residual z-score(|z|≥3)를 이상치 후보로 표기 (차트 점 표시)
4. 운영 관점 가설
2025-11-15 급락: 장애/점검/로그 누락/집계 파이프라인 이슈 가능성
근거: 요일 효과를 제거한 STL residual에서도 큰 감소가 보임 (설명 불가 하락)
2025-10-10 급등: UA/프로모션/대형 업데이트/외부 노출로 인한 단기 유입 급증 가능
근거: 다음날 감소 (증가가 지속되지않음) → 일회성 드라이브 패턴
주말 약세 구조: 유저 구성(신규/복귀/기존) 중 특정 세그먼트가 주말에 더 크게 빠지는 구조 가능
5. 권장 액션
원인 규명: 주말에 누가 빠지는가?를 먼저 분해
DAU 구성요소 분해: 신규 / 복귀 / 연속활성(기존)
코호트/리텐션: 주말 포함 코호트 vs 주말 미포함 코호트 비교
행동 동반지표: 세션수, 플레이타임, 핵심 콘텐츠 참여(던전/매칭), 결제/구매 시도
주말 트래픽 보완 액션 플랜
CASE 1(신규 이탈): 주말에 연속 출석 보상 강화(주말 보상 가중)
CASE 2(복귀 회전문): 복귀 후 3~7일 리텐션 미션(주말 포함 시 보상 업)
CASE 3(평일형 유저): 평일 콘텐츠 → 주말 변형/확장 콘텐츠로 주말 접속 명분 제공 주의 사항: 주말 이벤트는 주말 DAU/주말 잔존/주말 ARPPU/세션당 플레이타임을 함께 보며, 평일 지표 악화(피로도) 없는지 체크
이상치 대응 (ex. 11/15)
STL residual 기반 자동 알람 룰 (예: ㅣzㅣ≥3) + 장애 지표(로그인 실패/에러율/결제 실패) 연동
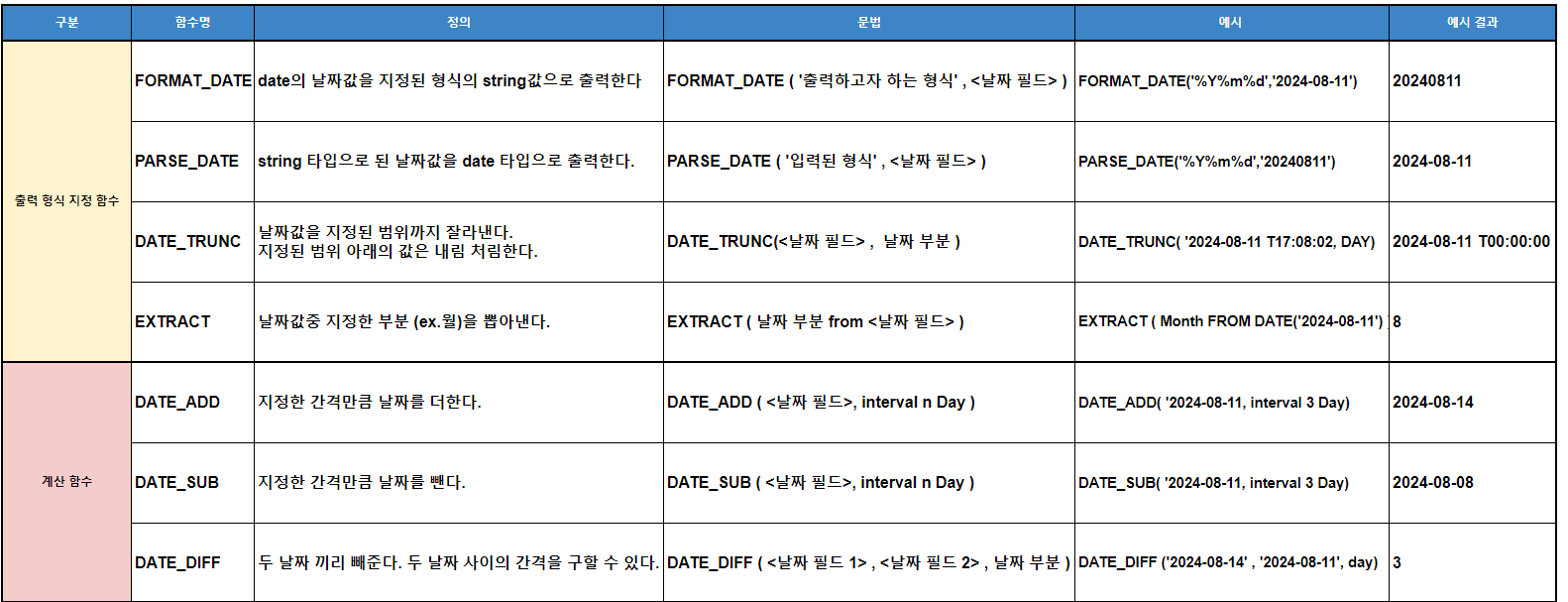
특히 PARSE_DATE은 날짜를 나타내는, ‘%Y-%m-%d 형식이 아닌 string값을 날짜 타입으로 변경할때 유용하다. ( ex. 20240825 -> 2024-08-25 )
DATE( ) 사용해서 날짜 타입으로 변경 많이 하는데 %Y-%m-%d 형식이 아닌 string 값은 DATE( ) 함수 사용시 에러가 난다. 이 경우 PARSE_DATE( ) 를 사용해야한다. substr과 concat함수를 이용해서 조합하는 방법도 있지만 구문이 길어지기 때문에 PARSE_DATE( ) 을 사용하는 것을 권장한다.
DB를 일별로 수집한다고 했을때 테이블의 _table_suffix가 ‘%Y%m%d’ 형식으로 되어있는 경우가 많다. 불러온 _table_suffix를 그대로 날짜 필드로 넣고 싶을때 PARSE_DATE를 쓰면 된다. ( 예시: PARSE_DATE(‘%Y%m%d’,_table_suffix) AS yyyymmdd )
3. Appendix
1) 다루고자 하는 날짜 타입 (Date, Datetime ,Timestamp )에 따라 함수명을 변경할 수 있다.
위에서 소개한 함수들은 DATE 타입을 기준으로 함수명을 써놓았는데 예시처럼 다 변경이 가능하다 ㄴ ex) FORMAT_DATE -> FORMAT_DATETIME , FORMAT_TIMESTAMP ㄴ ex) DATE_ADD -> DATETIME_ADD , TIMESTAMP_ADD
참고로 DATE와 DATETIME, TIMESTAMP는 표현할 수 있는 날짜 범위에 차이가 있다.
DATE : 날짜를 년, 월 , 일 까지 저장하고 있는 날짜 타입
DATETIME : 날짜를 년 , 월 , 일 , 시 , 분 , 초 ,초 미만으로 저장하고 있는 날짜 타입
TIMESTAMP : 날짜를 마이크로초단위 ( 초 이하 소숫점 6자리 ) 로 정밀하게 저장하고 있는 날짜 타입
TIMESTAMP는 빅쿼리상에서는 타임존이 같이 출력된다. ( ex: 2024-01-01 12:30:12.000000 UTC ) 빅쿼리 자체적으로는 마이크로초로 날짜값을 저장하고있는데 ( 고정된 초기 시점 이후 경과된 마이크로초 수 ) 표기시에 변환해서 출력해주면서 타임존까지 같이 나타내주는것이다.
행사 구성 : 3개의 강의실이 있고 각 강의실에서 연사가 강의하면 참가자가 원하는 강의를 듣는 형식 강의는 데이터 분석과 관련된 다양한 주제로 진행된다.
참여 후기
내가 데이터 야놀자 2024를 신청한 이유는 크게 2가지였다.
목표 1 : 다른 데이터 분석가들은 어떻게 분석을 하는지 알고싶었다.
목표 2 : 다른 데이터 분석가들과 네트워킹을 해보고 싶었다. 특히 게임업계!
결과적으로 데이터 야놀자 2024 행사를 통해 이 2가지 목표를 다 이룰 수 있었다.
우선, 연사들의 강연을 통해 목표 1을 달성할 수 있었다.
실제 분석 사례 (강연1. 지서영님) , 그리고 데이터 분석을 위한 자세 (강연 2.김선영님) 와 분석 방법론 (강연6.정이태님, 강연7.신진수님) 대해 들을 수 있었다. 강연을 듣고나니, 내가 생각하던것과 크게 다르지는 않아 다행이다 라는 생각이 듦과 동시에 앞으로 공부를 정말로 열심히 해야겠다라는 생각이 들었다.
( 강의 요약은 아래에 정리해두었다. )
모든 연사들이 강연에서 강조했던 것이 드릴 다운해서 분석하는 것이였다. 이 부분은 나도 인지하고 있는 부분이고 분석시에 실제로 하는 부분이라 다행이라는 생각이 들었다.
목표 2도 달성할 수 있었다. 게임업계에서 일하는 다양한 데이터 분석가분들을 만나 얘기를 나누며 각 회사에서 어떻게 데이터 분석을 하는지 , 고민하고 있는 문제는 무엇인지 등을 공유할 수 있는 뜻깊은 자리였다.
2. 강연 요약
강의명
강연자
영상 크리에이터 파헤치기
지서영 (넥슨)
드릴 다운, 분석가의 멘탈 모델
김선영(마켓핏랩)
2년만에 110배 성장을 만든 데이터 문화 이야기
홍서연(모요)
빅쿼리 Nested 칼럼을 CROSS JOIN으로 접근하면 데이터 분석을 망칩니다.
김진석 (아이오트러스트)
커뮤니티를 그래프 관점으로 분석하다면 어떨까? 실 커뮤니티 데이터를 기반으로 진행하는 그래프 데이터 분석
정이태 (GUG)
강연1. 영상 크리에이터 파헤치기
강연자 : 지서영 ( 넥슨 )
내용 :
컨텐츠의 가치 (화제성, 유지성)를 지표화 하는 일을 하고 있음
커스텀 지표를 만들어 제공 : ex) 반응도= (좋아요 + 댓글수) / 조회수 * 100
분석 대상을 드릴 다운하고 대상별로 분석 주제를 정함 : ex) 유튜브 -> 풀 영상 , 쇼츠 영상, 일반 VOD 영상
분석시 기준이 되는 수식 첨부 ex) 회귀식 기반 기울기
후기 :
커스텀 지표를 만들고 이를 기반으로 분석하는 것이 인상깊었다. 단 보는 사람입장에서는 익숙치 않은 지표기때문에 그 지표가 어떤 로직으로 이루어졌는지 같이 설명해줘야 한다는 것을 명심하자.
강연2. 드릴 다운 , 분석가의 멘탈 모델
강연자 : 김선영 (마켓핏랩)
내용 :
데이터 분석가에게 중요한 것은 드릴 다운하는 자세 ( 드릴 다운 : 측정 기준을 나눠서 판다 )
단순히 2차원 분석에서 끝나지 말고 3차원 이상 다차원 분석을 해라.
계속 고민하면서 나누고 쪼개라. 분석에 대한 집요함이 중요하다.
집요하게 분석하려면 후천적 호기심이 중요하다.
후천적 호기심을 기르는 대표적 방법 : 질문을 모아라. 단 맥락도 같이 수집하라. 맥락을 알아야 올바른 답을 줄 수 있다.
ex) 이 광고와 전환율의 상관 관계를 분석해줘.
맥락 : 최근 홈쇼핑 광고가 단가가 올랐다. 그래서 이 광고가 진짜 비용을 태울만큼 효과가 있는지 알고싶다. 맥락을 알면 질문자의 니즈에 맞는 분석을 해줄 수 있다.
드릴 다운할때는 업에 대한 이해 , 즉 도메인 지식이 중요하다
고객 세그먼트 분석, RFM 분석을 해보자
내 고객중 몇 %가 실제 매출의 대다수를 일으키는지? 이것을 알면 우리가 집중해야하는 고객군을 알수있다. 그러면 그 고객군에게 액션을 취할수 있다.
파레토 법칙 ( 20%의 고객이 80%의 매출을 일으킨다는 법칙 )이 적용되는지 데이터 확인
고객 세그먼트의 기준은 업에 특성에 따라 다르다. 그러니까 꼭 내 데이터 가지고 실제로 고객 세분화해보자. 그리고 이 과정을 끊임없이 반복하고 분석해야한다.
세그먼트를 나누는 것의 목적은 그 세그먼트에 따라 다른 액션을 취해서 성과(돈)를 일으키기 위해서이다.
후기 :
드릴 다운의 중요성을 다시금 느낄 수 있었다. 파레토 법칙을 평소에 분석하는 데이터에도 적용해보자.
강연3. 2년만에 110배 성장을 만든 데이터 문화 이야기
강연자 : 홍서연 (모요)
내용 :
스쿼드 단위로 프로젝트가 운영
각 스쿼드 : PO, PD (디자이너) , 기획자 , DA (데이터 분석가) 로 구성
데이터 분석가가 스쿼드마다 붙어서 긴밀하게 도움을 줌 : 데이터를 직접 분석해주고 다른 직군의 사람들이 데이터를 분석할 수 있게 환경 구축
로그 기획서 (테이블 명세서)를 전사 직원이 공유 : 로그가 어떻게 구성되어있는지 모든 직원들이 알고 있음.
믹스 패널을 이용해 분석 실험
분석 실험을 한 것은 모두 노션에 정리하여 공유하고 아카이빙함
후기 :
조직 구성원들이 기본적으로 로그에 대한 이해도를 갖추고 업무를 한다는게 인상깊었다. 그런데 한편으로는 조직 구성원들이 많지 않기 때문에 가능한것이 아닐까라는 생각도 들었다. 그리고 분석 실험을 한것을 모두 아카이빙해 공유하는 것이 데이터 기반 업무를 하는데 큰 도움이 될 것이라는 생각이 들었다.
강연4. 빅쿼리 Nested 칼럼을 CROSS JOIN으로 접근하면 데이터 분석을 망칩니다.
강연자 : 김진석 (아이오트러스트)
내용 :
구글 애널리틱스 to 빅쿼리 (GA to Big Query ) 할때 Nested 칼럼을 많이쓴다. 이때 UNNEST를 많이 이용하는데 이 방법은 문제가 있다.
Nested 칼럼 : 딕셔너리 형태로 되어있는 필드로 칼럼 안에서 특정 Key를 통해 Value를 조회한다.
Nested Repeated 칼럼 : Nested 필드가 한 레벨 더 들어가있는것 .칼럼 안에서 특정 key를 찾고 해당 Key와 동일한 레벨에 있는 value를 조회한다. 파이썬의 딕셔너리의 리스트 형태라고 이해하면 편하다.
Nested 칼럼은 키값으로 Value를 뽑아낼수있으니 굳이 Cross Join으로 필드 더 다루지말자
후기 :
효율적으로 테이블을 다루고 쿼리하는 방법을 연구한 것이 인상깊었다. 추후 데이터 마트를 설계할때 참고할 수 있을 것으로 보인다.
강연5. 커뮤니티를 그래프 관점으로 분석하다면 어떨까? 실 커뮤니티 데이터를 기반으로 진행하는 그래프 데이터 분석
강연자 : 정이태 ( GUG : 그래프 데이터 사이언티스트 )
내용 :
커뮤니티 : 자기 자신을 온,오프라인에 표현하며 타인과 교류 (집단,표현,소통)
기업이 커뮤니티에 관심을 갖는 이유 : 커뮤니티는 고객의 이야기인 ‘누가 사고 왜 사는지’를 듣고 의사결정을 할 수 있는 데이터가 모여있는곳
커뮤니티 비즈니스 사례 : ex) 레딧 : 레딧 애즈(ads) - 광고
데이터 제너레이션(Data generation) : 핵심.
관심사가 유사한 사람들끼리 의견 교류를 통해 발생한 자연 데이터를 활용
활용 방안
커뮤니티 성격에 맞는 적절한 글 배치
커뮤니티간 결합을 통해 재미 제공
익명성은 양날의 검, 이를 어떻게 잘 조절할지가 중요
그래프 : 데이터 간 연결 관계에 특화된 구조
Network 관점 - Node, Link / Graph 관점 - Vertex, Edge
그래프 데이터 장점 : 데이터간 연관성을 관리하고 활용하는데 편리함
~의 ~의 ~의에 특화
그래프 분석 : 모든 조합을 연결해보고 필터링해서 솔팅하는것
후기 :
강연에서 말한 커뮤니티가 게임사 입장에서는 길드라고 보면 될 것 같다. 그래프 분석이 관계 분석에 유용할 것으로 보이나 이를 위한 기반 작업이 상당히 필요할 것으로 보인다.
예를 들어 대부분의 DB가 RDB로 이루어져있는데 그래프 분석을 위한 DB를 별도로 세팅해야한다(GBMS) . 또한 각 그래프를 연결할때 넣어둔 메타 정보를 이용해서 관계를 지정하는데 새로운 메타 정보를 추가하려면 매번 로직을 새로 만들어줘야해서 실무에서 당장 적용하기는 어려워보인다. 추후 이 점만 개선된다면 활용하기 좋을 것 같다.
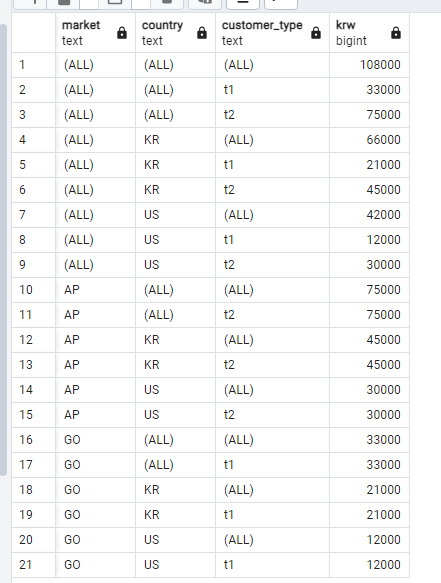
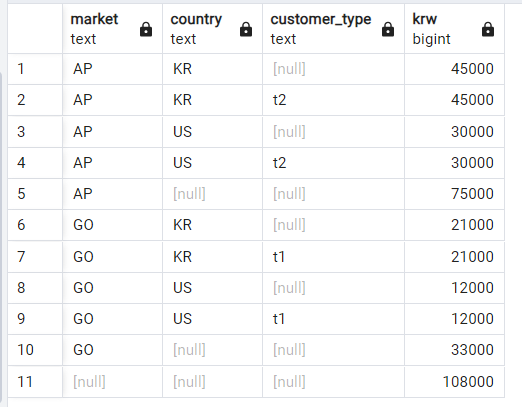
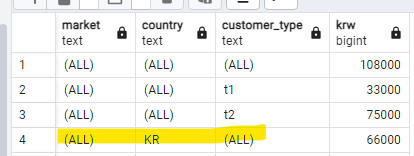
즉, 위의 rollup 구문은 인수인 market,country,customer 순으로 CUBE 계산을 하기 때문에 아래 이미지처럼 노란 형광펜으로 칠해진 부분을 구할수 없다.
어떻게 쿼리 구문을 짜야 모든 필드를 기준으로 소계를 구할수 있을까?
2.문제 해결
UNNEST를 이용하여 배열을 만들고 ,그 배열을 소계를 구하고자 하는 필드에 덮어씌워 GROUP BY 해줌으로써 이를 구현할 수 있다.
말이 복잡해보일 수 있는데 , 정리하자면 아래 구문을 이용한다고 보면 된다.
/* UNNEST([필드1,'전체']) AS 필드 1
GROUP BY 필드 1
*/SELECT필드1,SUM(won)ASkrwFROMsample_table,UNNEST([필드1,'전체'])AS필드1-- 기존 필드와 UNNEST문에서 배열을 풀면서 지정한 필드명은 동일해야함.WHERE1=1GROUPBY필드1
소계 계산할 칼럼을 UNNEST로 묶어준다. ‘전체’를 값으로 넣은 배열을 만들어주고 UNNEST 해줘서 풀어버린후 집계해준다. ( 전체 대신 “ALL”로 전체치를 표시하고 싶으면 ‘전체’ 대신 “ALL” 을 넣으면 된다)
이때 주의할점은 UNNEST문에서 배열을 풀어줄때 별칭으로 지정하는 필드명과 SELECT문에서 사용할 필드명이 동일해야 된다는 것이다.
지정하는 필드명이 동일해야 GROUP BY로 집계하면서 필드가 덮어씌어지는 효과가 난다. 만약 UNNEST문의 필드명을 SELECT문의 필드명과 다르게 지정한다면 해당 이름으로 된 필드가 하나 더 생기게 된다. 이렇게 될 경우 헷갈릴 가능성이 크므로 위의 예시처럼 필드명을 동일하게 지정하는 것이 좋다.