(SQL) 윈도 함수를 이용해 데이터 가공하기
(SQL) 윈도 함수를 이용해 데이터 가공하기
✋🏾 PostgreSQL을 이용하여 쓰인 포스팅입니다.
윈도함수란 테이블 내부에 ‘윈도’라는 범위 를 정의하고 , 해당 범위 내부에 포함된 값을 자유롭게 사용하려고 도입한 것이다.
즉, 자체적으로 범위를 정해 그 안에서 작업하기 위한 함수이다.
윈도함수를 통해 데이터를 집약하거나 그룹 내부의 순서를 배열할 수 있다.
윈도 함수를 사용하기 위해서는 윈도 함수 내부에
참조하고자하는 값의 위치를 명확하게 지정해야 한다.
OVER 구문 내부에 ORDER BY 구문을 사용하여 윈도 내부에 있는 데이터의 순서를 정의한다.
일반적인 윈도 함수 , 특히 OVER 구문은 다음과 같다.
SELECT <칼럼명>
, <함수> () OVER(PARTITION BY <칼럼명> ORDER BY <칼럼명> DESC ROWS BETWEEN "start" AND "end" )
FROM <테이블명>
윈도우 함수 사용시 주목할 부분이 네 군데가 있다.
SELECT <칼럼명>
, <함수> () OVER(PARTITION BY <칼럼명> ORDER BY <칼럼명> DESC ROWS BETWEEN "start" AND "end" )
FROM <테이블명>
1) <함수> </b>
SELECT 다음에 <함수> 부분을 살펴보자.
이때 <함수>에는 다양한 함수가 사용가능하다.
집계할때 많이 사용하는 SUM( )이나 COUNT( ),MAX( ),MIN( ) 함수 모두 가능하다.
특히 순서를 배열할때는 row_number( ) 함수나 rank() 함수, dense_rank( ) 함수가 주로 쓰인다.
ROW_NUMBER(): 점수 순서로 유일한 순위를 붙임
RANK() : 같은 순위를 허용해서 순위를 붙임
DENSE_RANK() : 같은 순위가 있을 때 같은 순위 다음에 있는 순위를 건너 띄고 순위를 붙임
2) PARTITION BY <칼럼명> </b>
두번째는 OVER( ) 다음에 바로 나오는 PARTITION BY <칼럼명> 이다.
PARTITION BY <칼럼명> 은 윈도함수 내부에서 데이터를 집약할 때 사용한다.
윈도함수 내부에서 GROUP BY를 해준다고 보면 되며
결과적으로 지정해준 <칼럼명> 필드 안에서 윈도우를 나눠서 집계한다고 생각하면 된다.
윈도 함수에서 특정 칼럼으로 집약하지 않고 순서 배열만 한다면 생략해도 무방하다.
3) ORDER BY <칼럼명> </b>
세번째는 ORDER BY <칼럼명>이다. 윈도우를 세팅하는 과정이다.
윈도우를 어떤 필드를 기준으로 정렬(내림차순 or 오름차순)할지 정하는 것이다.
윈도우 내부를 어떤 순서로 구성할지 이해하면 편하다.
4) ROWS BETWEEN “start” AND “end”
마지막으로, OVER( )구문 안에 ROWS BETWEEN “start” AND “end”를 보자.
이것을 프레임 지정 구문이라고 한다.
프레임 지정이란 현재 레코드 위치를 기반으로 상대적인 윈도를 정의하는 구문이다.
“start”와 “end”에는 다음 키워드가 들어갈 수 있다.
- CURRENT ROW : 현재의 행
- n PRECEDING : n행 앞
- n FOLLOWING : n행 뒤
- UNBOUNDED PRECEDING : 이전 행 전부
- UNBOUNDED FOLLOWING : 이후 행 전부
두가지 예시를 통해 윈도함수 대해 더 알아보자.
다음은 인기 있는 상품이 기록된 popular_products 테이블이다.
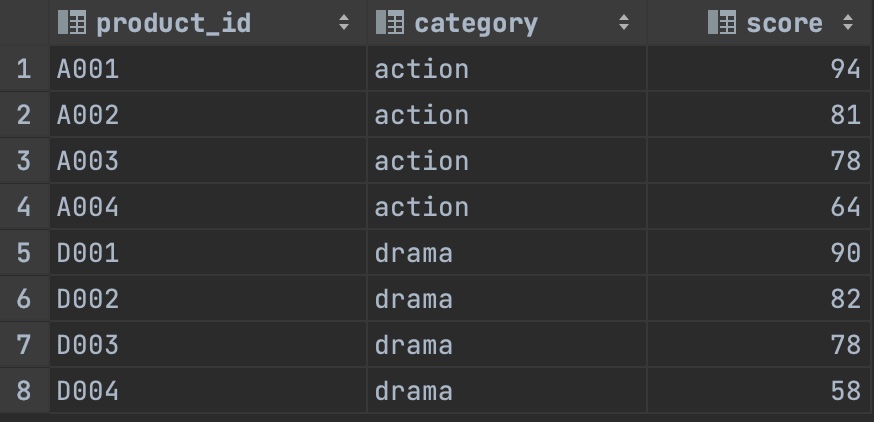
나는 윈도함수를 사용해 카테고리들의 순위를 계산하고 싶다.
다음 네가지를 한 테이블에 추출하고싶다.
1) 카테고리별로 점수 순서로 정렬하고 유일한 순위를 붙임
2) 카테고리별로 같은 순위를 허가하고 순위를 붙임
3) 카테고리별로 같은 순위가 있을 때 같은 순위
4) 다음에 있는 순위를 건너 띄고 순위를 붙임
이럴 경우, 윈도함수를 사용하면 추출할 수 있다.
SELECT
category
, product_id
, score
, ROW_NUMBER() over (PARTITION BY category ORDER BY score DESC) AS row
, RANK() OVER(PARTITION BY category ORDER BY score DESC) AS rank
, DENSE_RANK() OVER(PARTITION BY category ORDER BY score DESC) AS dense_rank
FROM popular_products
ORDER BY category,row;
결과가 다음과 같이 나온다.
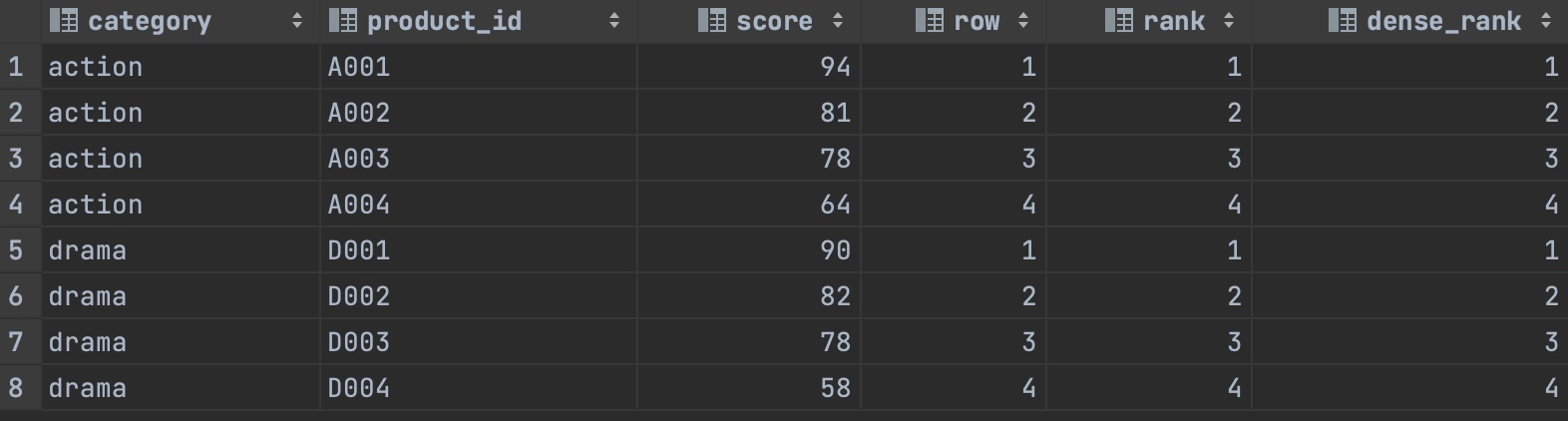
두번째 예시다.
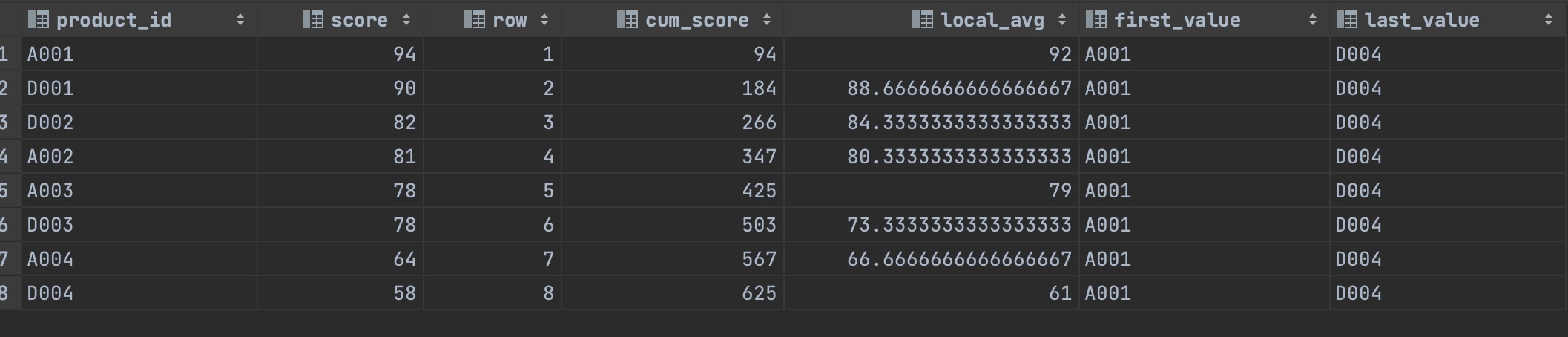
윈도 함수를 이용해 카테고리별 주요 수치를 추출하고 싶다.
1) 점수 순서로 유일한 순위
2) 순위 상위부터의 누계 점수 계산
3) 현재 행과 앞 뒤의 행이 가진 값을 기반으로 평균 점수 계산하기
4) 순위가 높은 상품 ID 추출하기
SELECT
product_id
,score
, row_number() over (ORDER BY score DESC) AS row -- 점수 순서로 유일한 순위를 붙임
,SUM(score) OVER (ORDER BY SCORE DESC ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW ) AS cum_score -- 순위 상위부터 누계 점수 계산하기
,AVG(score) OVER (ORDER BY score DESC ROWS BETWEEN 1 PRECEDING AND 1 FOLLOWING) AS local_avg -- 현재 행과 앞 뒤의 행이 가진 값을 기반으로 평균 점수 계산하기
,FIRST_VALUE(product_id) OVER(ORDER BY SCORE DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS first_value -- 순위가 높은 상품 ID 추출하기
,LAST_VALUE(product_id) OVER(ORDER BY SCORE DESC ROWS BETWEEN UNBOUNDED PRECEDING AND UNBOUNDED FOLLOWING) AS last_value -- 순위가 낮은 상품 ID 추출하기
FROM popular_products
;
결과가 다음과 같이 나온다.