(Python) 엑셀 파일 쪼개기 _이름을 기준으로
파이썬을 이용해 엑셀 파일을 분할하자
(python) 파이썬으로 엑셀 파일 쪼개기
각 사원들의 실적이 기록되어 있는 엑셀 파일이 있다.
실적 입력과 검수를 다 완료한 후 , 각 사원에게 본인의 실적이
기록된 엑셀 파일을 메일로 개별 전송하려고 한다.

엑셀을 일일이 열어서 파일을 개인별로 별도로
저장하는 것은 시간과 정확도에서 모두 비효율적이다.
이런 상황에서는 어떻게 해야할까?
파이썬을 이용해 엑셀 파일을 분할해 저장하는 작업을 할 것이다.
사원명을 기준으로 파일을 분할해보자
이 작업을 위해 판다스의 loc 구문과 to_excel,ExcelWriter구문을 활용한다.
예시코드를 아래에서 소개하겠다.
# 모듈 임포트 (판다스, 넘파이)
import pandas as pd
from pandas import ExcelWriter
import numpy as np
우선 판다스와 넘파이 모듈을 임포트해준다.
참고로 판다스와 넘파이 모듈은 데이터 작업을 할 때
자주 사용되니 기본적으로 임포트해주는게 편하다.
# 엑셀 파일 읽기
sheet_1 = pd.read_excel("경로",header= , sheet_name= "")
sheet_2 = pd.read_excel("경로",header= , sheet_name= "")
엑셀을 시트별로 불러온다.
pd.read_excel 구문을 이용하여 엑셀파일을 불러온다.
pd.read_excel의 파라미터에 따라 , 원하는 옵션대로 불러올 수 있다.
pd.read_excel의 파라미터는 다음과 같다.
pd.read_excel ("경로", sheet_name="", header= , names= "", nrows= "" )
- 경로 : 불러오기 할 파일 경로
- sheet_name : 엑셀 파일에서 불러올 시트명 지정 ( 디폴트 값은 0이며, 별도로 지정하지 않으면 첫번째 시트가 설정된다.)
- header : 열 이름으로 사용할 행을 지정 ( 디폴트 값은 0이며, 별도로 지정하지 않으면 첫 행을 열의 이름으로 자동 지정된다.)
- names : 열의 이름을 리스트 형태로 지정한다. ( 디폴트 값은 None이다.)
- index_col : 인덱스로 사용할 열의 이름 또는 열의 번호를 지정한다. (생략하면 원본 데이터에 없는 0 부터 시작하는 행 번호가 첫번째 열에 추가된다.)
- usecols : 파일에서 읽어올 데이터의 열을 선택 ( 디폴트 값은 None이며, 별도로 지정하지 않으면 전체 열이 선택된다. 데이터로 가져올 열을 지정하는 방법은 콤마 또는 콜론으로 지정할 수 있다.
- nrows : 불러올 row 수
# 이름이 저장된 리스트 만들기 ( 인덱스 만들기 )
staff=np.unique(sheet_1["이름"].values).tolist() # 사원명 리스트 출력
이름이 저장된 리스트를 별도로 만들어
이름 칼럼을 기준으로 for문을 돌릴 것이다.
그러면 각각의 이름별로 파일이 분할된다.
파일을 분할하기 위해서 다음 코드를 응용할 것이다.
for s in staff:
#1 파일명 생성
file_name='.\_{}.xlsx'.format(s) # 파일이름 설정 (경로 포함)
#2 저장할 데이터프레임 생성
staff_save_df=df.loc[['staff_col']==s]
#3 스태프 데이터프레임 저장되어있는
staff_save_df.to_excel(file_name)
한 시트만 저장한다면 위 코드로 충분하지만 한 파일에 여러 시트를
저장하려면 판다스의 ExcelWriter 구문을 활용해야한다.
# 파일명 생성
# 칼럼명 선택
for s in staff_name:
file_name=".\파일이름_{}.xlsx".format(s) # 파일 이름(경로 포함) 설정
writer=pd.ExcelWriter(file_name,engine="xlsxwriter") # 시트 합치기 위해, xlsxwriter 사용
# 시트별로 데이터 프레임 만들기
staff_save_df_1=sheet_1.loc[sheet_1["칼럼명"]== "조건"]
staff_save_df_2=sheet_2[sheet_2["칼럼명"]== "조건"]
staff_save_df_3=sheet_2.loc[sheet_2["칼럼명"]== "조건" ]
# 엑셀 파일로 변환
staff_save_df_1.to_excel(writer,sheet_name="설정하고자 하는 시트이름") # staff_save_df_1 : 분할 파일 1번 시트에 들어감
staff_save_df_2.to_excel(writer,sheet_name="설정하고자 하는 시트이름") # staff_save_df_2 : 분할 파일 2번 시트에 들어감
staff_save_df_3.to_excel(writer,sheet_name="설정하고자 하는 시트이름") # staff_save_df_3 : 분할 파일 3번 시트에 들어감
writer.save()
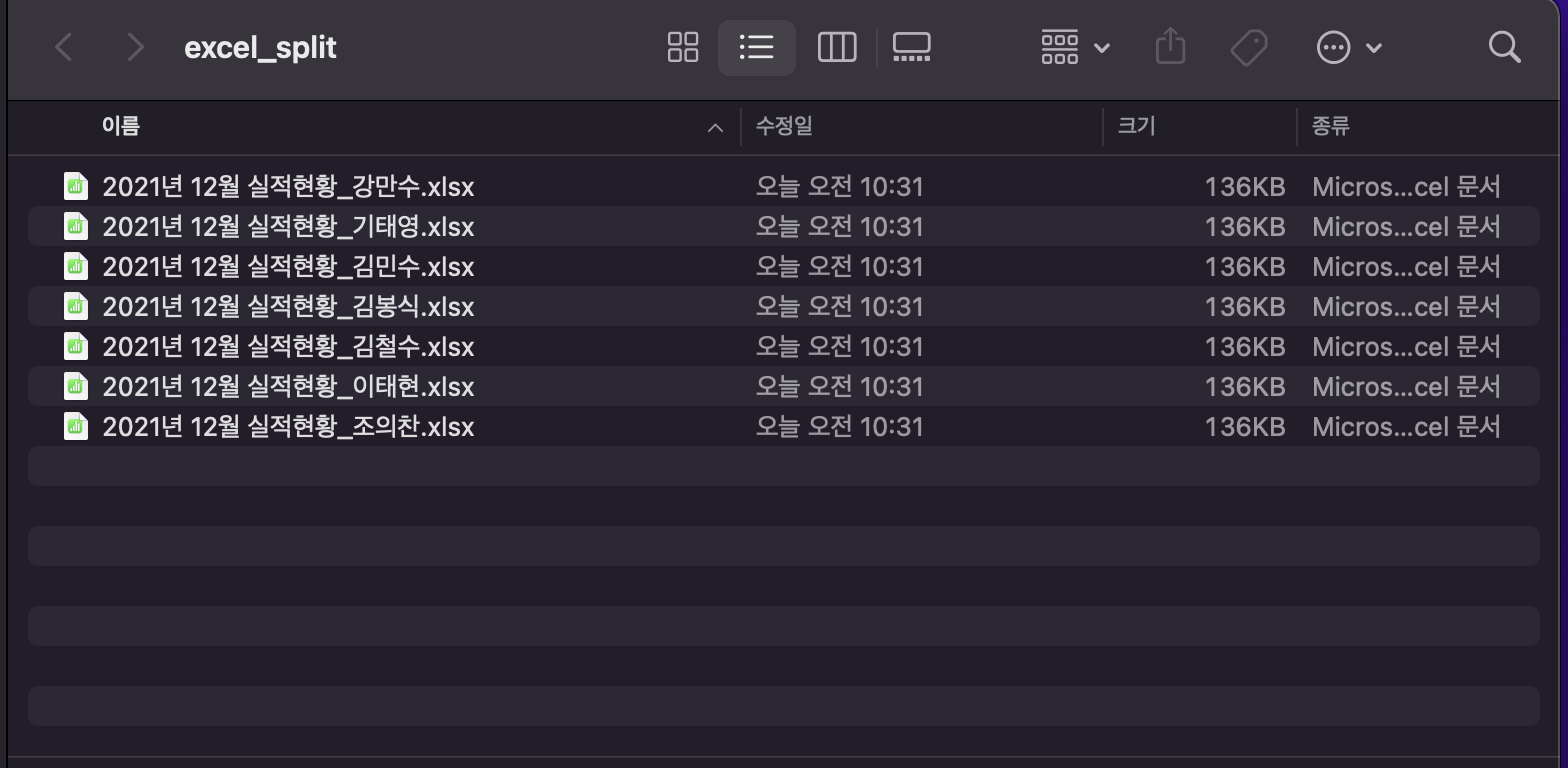
이렇게 하면 엑셀파일을 이름 기준으로 각각의 파일로 분할할 수 있다.
처음 소개한 예시상황에 대입하면 코드는 다음과 같다.
import pandas as pd
from pandas import ExcelWriter
import numpy as np
sheet_1 = pd.read_excel("./excel_split/2021년 12월 실적현황.xlsx" ,header=0 , sheet_name= "MAIN")
sheet_2 = pd.read_excel("./excel_split/2021년 12월 실적현황.xlsx" ,header=0 , sheet_name= "RAW")
staff=np.unique(sheet_1["이름"].values).tolist()
for s in staff:
file_name="./excel_split/2021년 12월 실적현황_{}.xlsx".format(s) # 파일 이름(경로 포함) 설정
writer=pd.ExcelWriter(file_name,engine="xlsxwriter") # 시트 합치기 위해, xlsxwriter 사용
# 시트별로 데이터 프레임 만들기
staff_save_df_1=sheet_1.loc[sheet_1["이름"]==s]
staff_save_df_2=sheet_2[sheet_2["이름"]== "s"] # 시트 2도 이름별로 분할
staff_save_df_2=staff_save_df_2[staff_save_df_2["인센티브"]=="대상"]] # 추가 조건있다면 설정
# 엑셀 파일로 변환
staff_save_df_1.to_excel(writer,sheet_name="MAIN") # staff_save_df_1 : 분할 파일 1번 시트에 들어감
staff_save_df_2.to_excel(writer,sheet_name="MAIN_INCEN") # staff_save_df_2 : 분할 파일 2번 시트에 들어감
writer.save()
