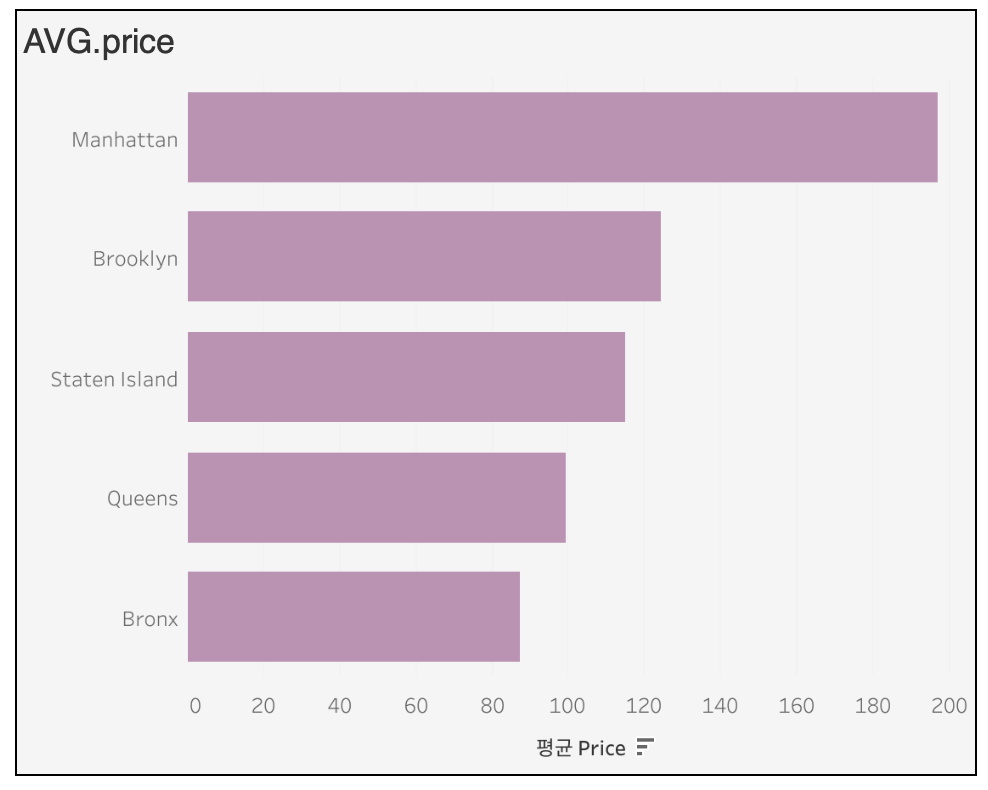
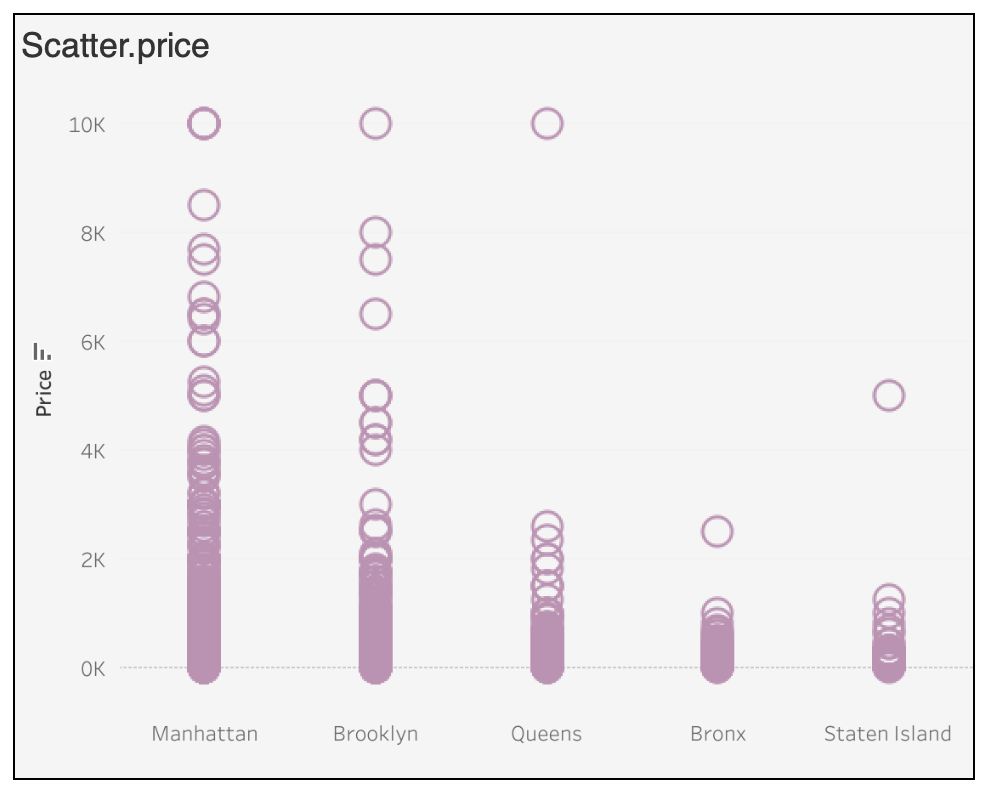
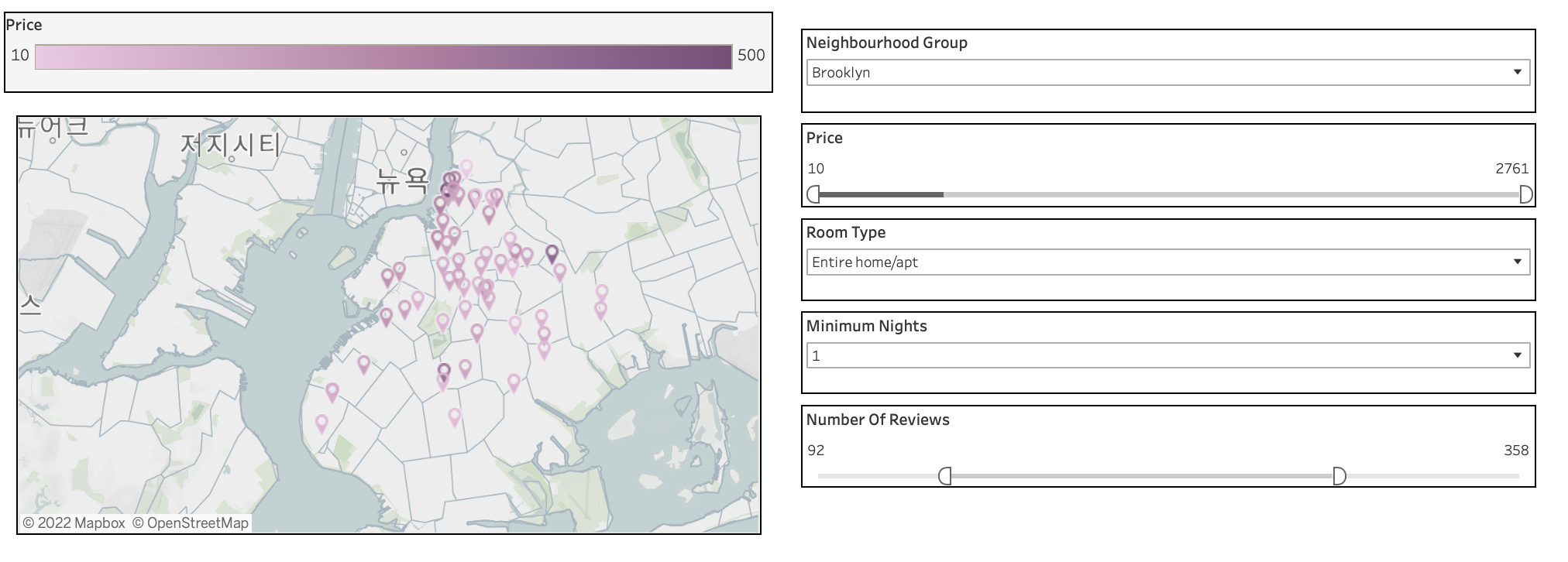
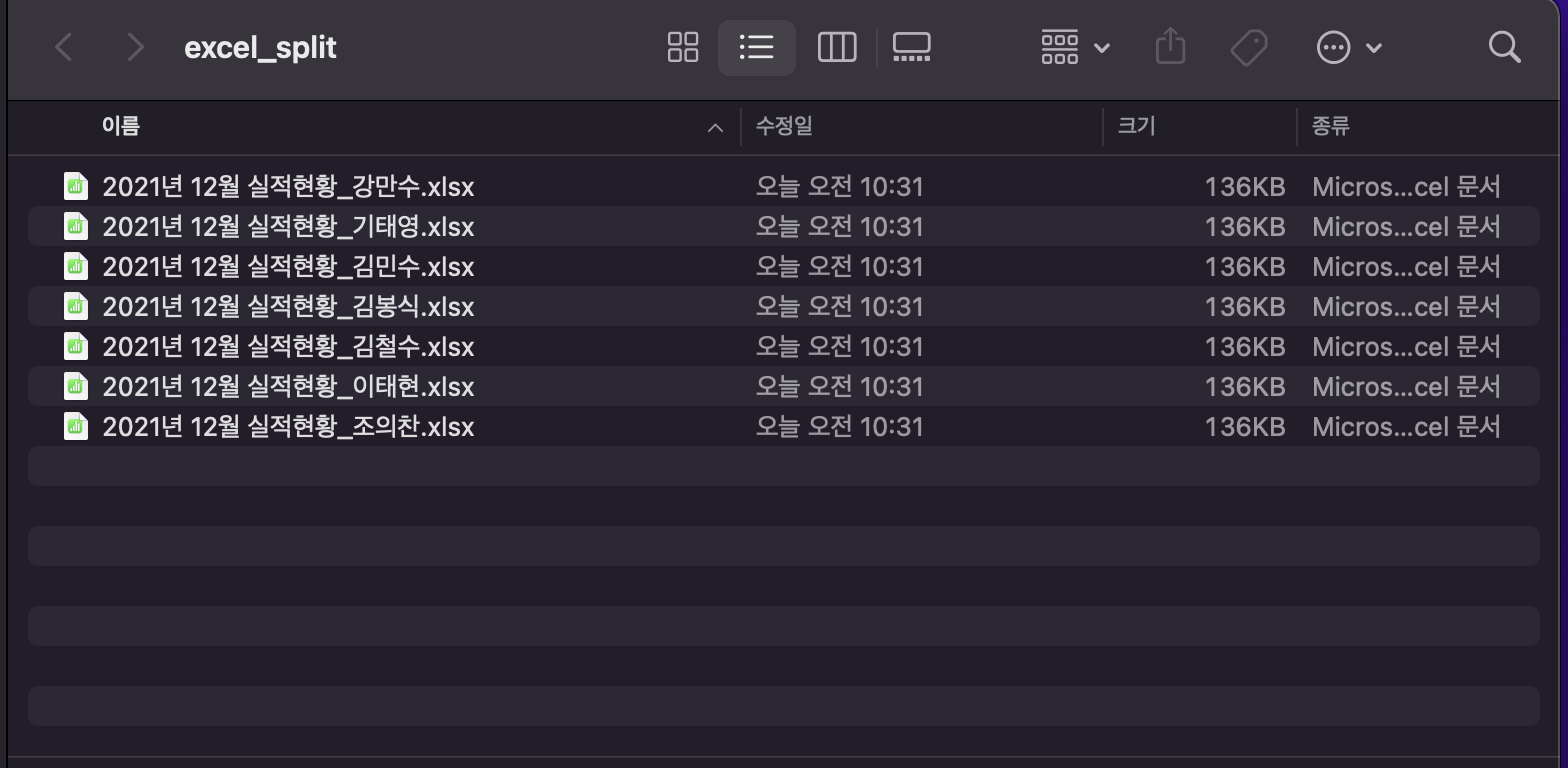
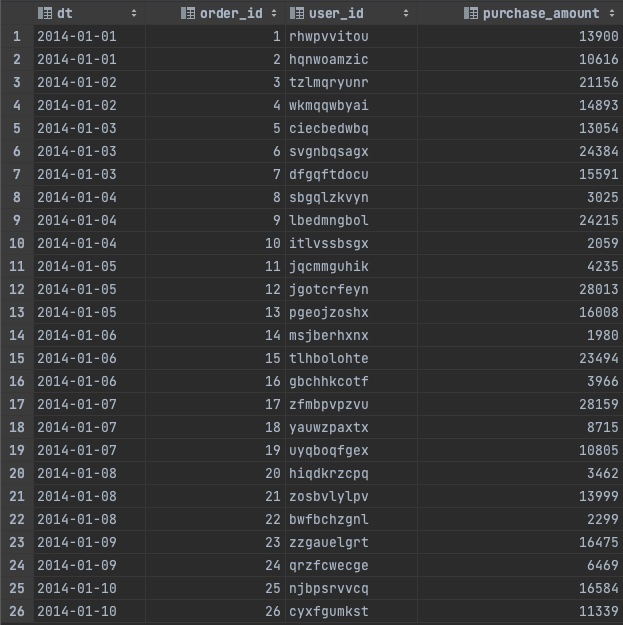
sheet_name : 엑셀 파일에서 불러올 시트명 지정 ( 디폴트 값은 0이며, 별도로 지정하지 않으면 첫번째 시트가 설정된다.)
header : 열 이름으로 사용할 행을 지정 ( 디폴트 값은 0이며, 별도로 지정하지 않으면 첫 행을 열의 이름으로 자동 지정된다.)
names : 열의 이름을 리스트 형태로 지정한다. ( 디폴트 값은 None이다.)
index_col : 인덱스로 사용할 열의 이름 또는 열의 번호를 지정한다. (생략하면 원본 데이터에 없는 0 부터 시작하는 행 번호가 첫번째 열에 추가된다.)
usecols : 파일에서 읽어올 데이터의 열을 선택 ( 디폴트 값은 None이며, 별도로 지정하지 않으면 전체 열이 선택된다. 데이터로 가져올 열을 지정하는 방법은 콤마 또는 콜론으로 지정할 수 있다.
nrows : 불러올 row 수
# 이름이 저장된 리스트 만들기 ( 인덱스 만들기 )
staff=np.unique(sheet_1["이름"].values).tolist()# 사원명 리스트 출력
이름이 저장된 리스트를 별도로 만들어 이름 칼럼을 기준으로 for문을 돌릴 것이다. 그러면 각각의 이름별로 파일이 분할된다.
파일을 분할하기 위해서 다음 코드를 응용할 것이다.
forsinstaff:#1 파일명 생성
file_name='.\_{}.xlsx'.format(s)# 파일이름 설정 (경로 포함)
#2 저장할 데이터프레임 생성
staff_save_df=df.loc[['staff_col']==s]#3 스태프 데이터프레임 저장되어있는
staff_save_df.to_excel(file_name)
한 시트만 저장한다면 위 코드로 충분하지만 한 파일에 여러 시트를 저장하려면 판다스의 ExcelWriter 구문을 활용해야한다.
# 파일명 생성
# 칼럼명 선택
forsinstaff_name:file_name=".\파일이름_{}.xlsx".format(s)# 파일 이름(경로 포함) 설정
writer=pd.ExcelWriter(file_name,engine="xlsxwriter")# 시트 합치기 위해, xlsxwriter 사용
# 시트별로 데이터 프레임 만들기
staff_save_df_1=sheet_1.loc[sheet_1["칼럼명"]=="조건"]staff_save_df_2=sheet_2[sheet_2["칼럼명"]=="조건"]staff_save_df_3=sheet_2.loc[sheet_2["칼럼명"]=="조건"]# 엑셀 파일로 변환
staff_save_df_1.to_excel(writer,sheet_name="설정하고자 하는 시트이름")# staff_save_df_1 : 분할 파일 1번 시트에 들어감
staff_save_df_2.to_excel(writer,sheet_name="설정하고자 하는 시트이름")# staff_save_df_2 : 분할 파일 2번 시트에 들어감
staff_save_df_3.to_excel(writer,sheet_name="설정하고자 하는 시트이름")# staff_save_df_3 : 분할 파일 3번 시트에 들어감
writer.save()
이렇게 하면 엑셀파일을 이름 기준으로 각각의 파일로 분할할 수 있다. 처음 소개한 예시상황에 대입하면 코드는 다음과 같다.
importpandasaspdfrompandasimportExcelWriterimportnumpyasnpsheet_1=pd.read_excel("./excel_split/2021년 12월 실적현황.xlsx",header=0,sheet_name="MAIN")sheet_2=pd.read_excel("./excel_split/2021년 12월 실적현황.xlsx",header=0,sheet_name="RAW")staff=np.unique(sheet_1["이름"].values).tolist()forsinstaff:file_name="./excel_split/2021년 12월 실적현황_{}.xlsx".format(s)# 파일 이름(경로 포함) 설정
writer=pd.ExcelWriter(file_name,engine="xlsxwriter")# 시트 합치기 위해, xlsxwriter 사용
# 시트별로 데이터 프레임 만들기
staff_save_df_1=sheet_1.loc[sheet_1["이름"]==s]staff_save_df_2=sheet_2[sheet_2["이름"]=="s"]# 시트 2도 이름별로 분할
staff_save_df_2=staff_save_df_2[staff_save_df_2["인센티브"]=="대상"]]# 추가 조건있다면 설정
# 엑셀 파일로 변환
staff_save_df_1.to_excel(writer,sheet_name="MAIN")# staff_save_df_1 : 분할 파일 1번 시트에 들어감
staff_save_df_2.to_excel(writer,sheet_name="MAIN_INCEN")# staff_save_df_2 : 분할 파일 2번 시트에 들어감
writer.save()
예를 들어 7일간 이동평균은 1~7일 평균, 2~8일 평균, 3~9일 평균 … 처럼 가장 오래된 데이터 대신에 최신의 데이터를 넣어 평균을 구하는 것을 말한다.
즉, 이동평균은 정해진 기간에서의 데이터의 평균이라고 할 수 있다.
2. 이동평균 구하는 구문?
이동평균을 구하기 위해서, 윈도 함수인 OVER( ORDER BY ~) 구문을 활용해주어야 한다. 윈도함수를 통해 7일씩 데이터를 쪼개서 계산하는것이 원리이다.
이동평균을 구하는 구문은 다음과 같다.
SELECT<날짜칼럼>,AVG(SUM(구하고자하는칼럼))OVER(ORDERBY<날짜칼럼>ROWSBETWEEN6PRECEDINGANDCURRENTROW)ASavg_7,-- 최근 최대 7일동안의 이동평균CASEWHENcount(*)OVER(ORDERBY<날짜칼럼>ROWSBETWEEN6PRECEDINGANDCURRENTROW)=7THENAVG(SUM(구하고자하는칼럼))OVER(ORDERBYdtROWSBETWEEN6PRECEDINGANDCURRENTROW)ENDASavg_7_strict-- 최근 7일 동안의 평균을 확실하게 계산하기FROM<테이블명>GROUPBY<날짜칼럼>;
위의 구문을 보면 이동평균 구하는 것을 2가지 방법으로 나누어 놓은 것을 볼 수 있다.
최근 최대 7일 동안의 이동평균
무조건 7일 동안의 평균
첫번째 방법은 7일의 기간이 충족되지 않는 1~6일도 있는 기간까지의 평균이 구해지는 방법이다.
반면 두번째 방법인 CASE 구문을 이용한 이동평균 구하기 방법은 무조건 기간이 7일이 되었을때 평균을 구하는 것이다.
3. 예제
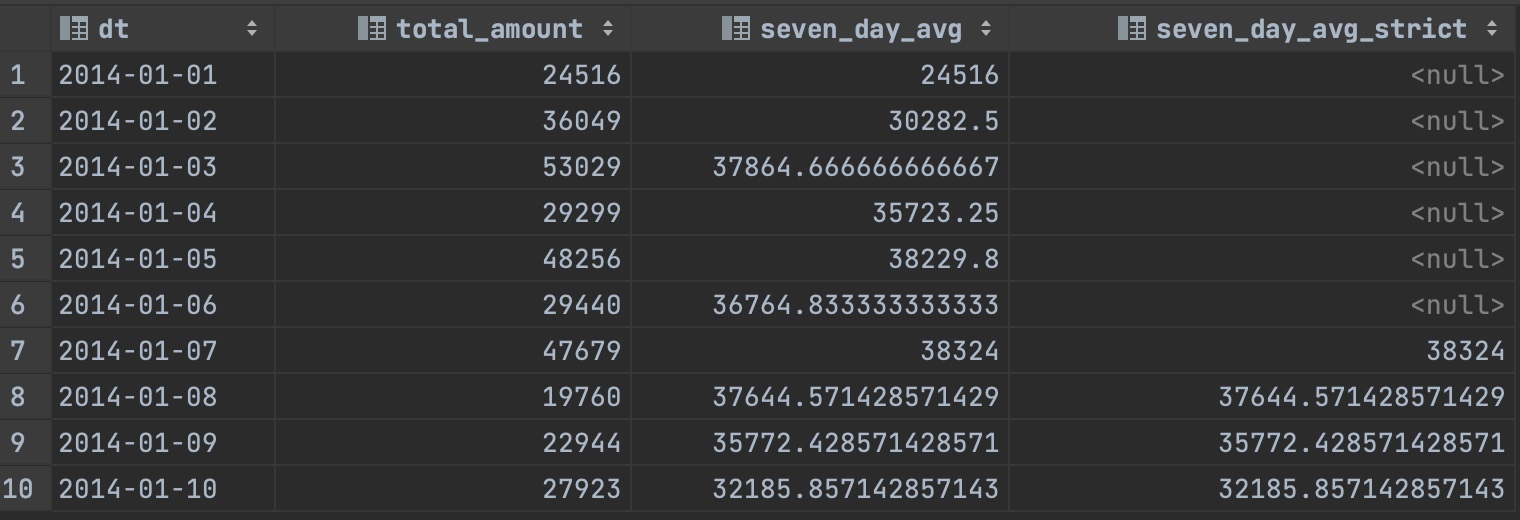
다음 매출 데이터를 보자.
이 매출 데이터를 위에서 소개한 쿼리를 이용해 날짜별 매출과 7일 이동평균을 집계하는 결과물을 출력해보자
SELECTdt,SUM(purchase_amount)AStotal_amount,AVG(SUM(purchase_amount))OVER(ORDERBYdtROWSBETWEEN6PRECEDINGANDCURRENTROW)ASseven_day_avg,-- 최근 최대 7일 동안의 평균 계산하기.CASEWHENcount(*)OVER(ORDERBYdtROWSBETWEEN6PRECEDINGANDCURRENTROW)=7THENAVG(SUM(purchase_amount))OVER(ORDERBYdtROWSBETWEEN6PRECEDINGANDCURRENTROW)ENDASseven_day_avg_strict-- 최근 7일 동안의 평균을 확실하게 계산하기FROMpurchase_logGROUPBYdtORDERBYdt;
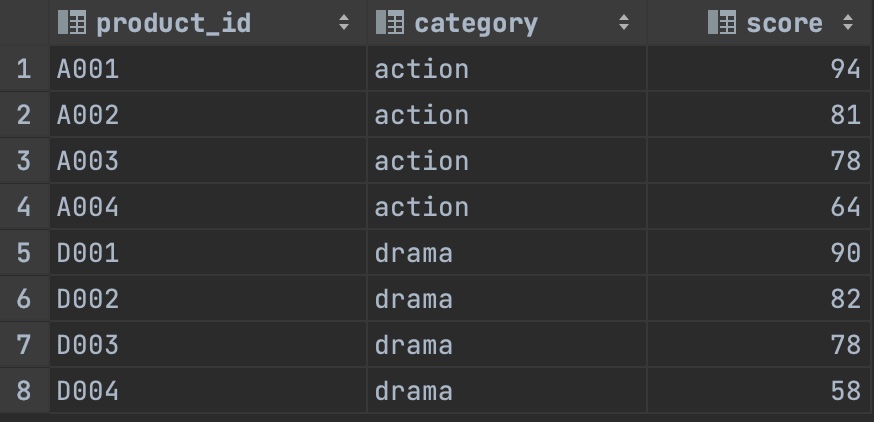
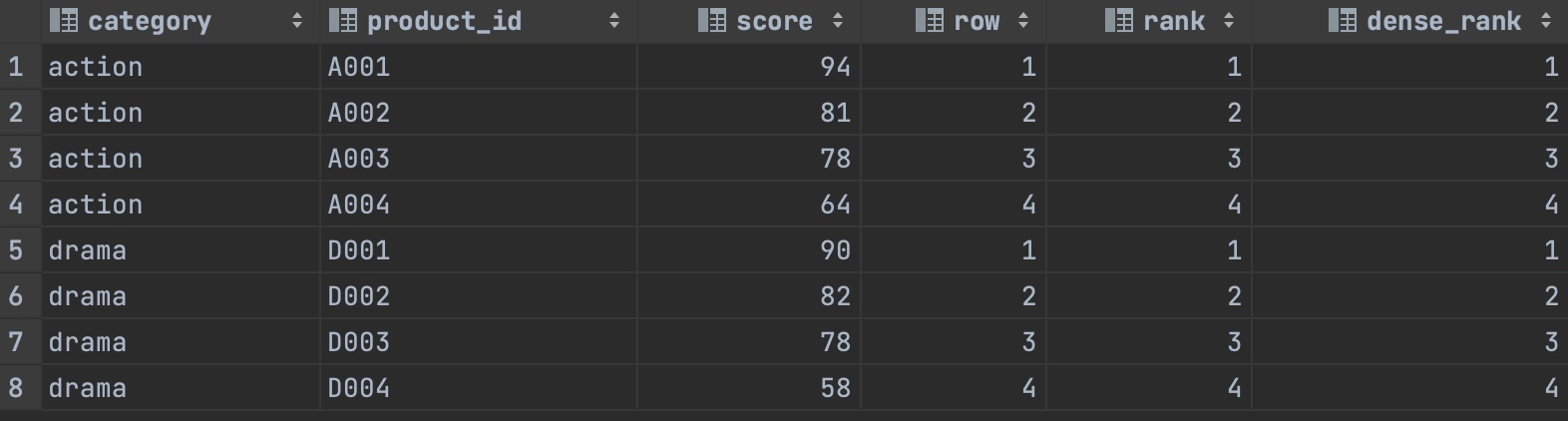
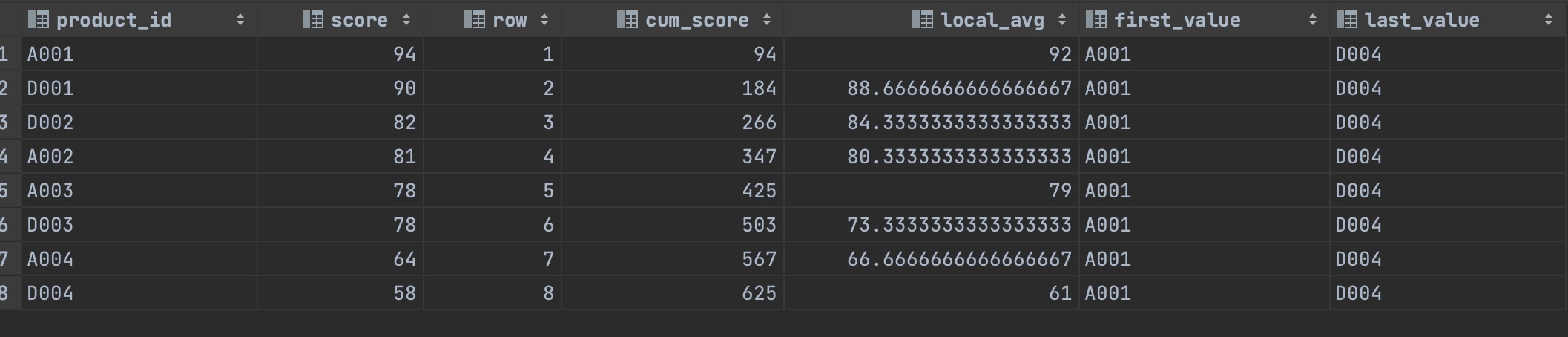
1) 점수 순서로 유일한 순위 2) 순위 상위부터의 누계 점수 계산 3) 현재 행과 앞 뒤의 행이 가진 값을 기반으로 평균 점수 계산하기 4) 순위가 높은 상품 ID 추출하기
SELECTproduct_id,score,row_number()over(ORDERBYscoreDESC)ASrow-- 점수 순서로 유일한 순위를 붙임,SUM(score)OVER(ORDERBYSCOREDESCROWSBETWEENUNBOUNDEDPRECEDINGANDCURRENTROW)AScum_score-- 순위 상위부터 누계 점수 계산하기,AVG(score)OVER(ORDERBYscoreDESCROWSBETWEEN1PRECEDINGAND1FOLLOWING)ASlocal_avg-- 현재 행과 앞 뒤의 행이 가진 값을 기반으로 평균 점수 계산하기,FIRST_VALUE(product_id)OVER(ORDERBYSCOREDESCROWSBETWEENUNBOUNDEDPRECEDINGANDUNBOUNDEDFOLLOWING)ASfirst_value-- 순위가 높은 상품 ID 추출하기,LAST_VALUE(product_id)OVER(ORDERBYSCOREDESCROWSBETWEENUNBOUNDEDPRECEDINGANDUNBOUNDEDFOLLOWING)ASlast_value-- 순위가 낮은 상품 ID 추출하기FROMpopular_products;