in 가이던스 on 데이터 기초 주제별 데이터셋 다운로드 사이트 총정리!
주제별 데이터셋 다운로드 사이트 총정리!
공공데이터
공공데이터 관련해서 각 부처가 별도의 사이트를 운영하고 있는 경우가 많다.
분석주제와 관련된 부처의 빅데이터 사이트를 들어가보자.
- 공공데이터 포털 : 공공데이터를 분야별로 종합해서 모아놓은 곳
- 서울 열린데이터 광장 : 서울시가 운영하는 공공데이터포털
- 경기 데이터드림 : 경기도가 운영하는 공공데이터포털
- 한국관광 데이터랩 : 한국관광공사에서 운영하고 있는 데이터셋 관련 사이트.
- 관광방문객수 데이터 제공
- 광역지자체 관광지출액 데이터 제공
- 관광수지, 기타 관광관련 데이터 제공
- 우리지역 관광상황판, 관광이슈분석 등 간단한 분석도 제공
- 국토교통부 데이터 통합 채널
- 국토교통 해커톤 수상작, 국민 참여 분석 프로젝트 소개
- 주택관련 데이터 : 공동주택 공시가격 데이터
- 교통물류 관련 데이터 : 자동차 등록대수 데이터
- 항공 안전현황 관련 데이터
- 국가 공간정보 포털
- 지적도 관련 데이터 제공
- 지형도 관련 데이터 제공
- 도로, 국토계획 관련 데이터 제공
- 국가 대중교통 정보센터
- 네이버지도(대중교통) 경로검색 데이터 제공
- 카카오맵(대중교통) 경로검색 데이터 제공
- 국가 물류 통합정보센터
- 내륙화물 통계 데이터 제공
- 항공화물 통계 데이터 제공
- 운송수단 통계 데이터 제공
- 생활물류 통계 데이터 제공
데이터 거래소
데이터 거래소는 데이터를 사거나 팔 수 있는 플랫폼이다.
민간기업에서 제공하는 데이터를 살 수 있다.
in 가이던스 on Python OR 과 isin()을 이용한 인덱싱
(python) 칼럼의 값에 따라 행 뽑기 (열과 행 혼합 인덱싱)
1. 문제 발생

위와 같은 데이터프레임이 있다.
이 데이터프레임에서 ‘country’ 열의 값이 ‘IT’ 이거나 ‘JP’인 행을 뽑고싶다.
어떻게 해야할까?
# 예제 데이터프레임
df_clean=pd.DataFrame({'country': ['IT','JP','KR','FR']
, 'income':[100,200,300,400]})
2. 문제 해결
크게 2가지 방법이 있다.
첫번째 방법은 or 을 사용하는 것이다.
df_clean[(df_clean['country']=="IT") | (df_clean['country']=="JP")]
또다른 방법은 isin()을 이용하는 것이다.
value_list=["IT","JP"]
df_clean[df_clean['country'].isin(value_list)]
isin( )은 output으로 boolean(True,False) 값을 반환한다.
따라서 위와 같이 인덱싱이 가능하다.
3. 배운 점 및 피드백
- 어러 값을 가지고 있는 리스트가 있을 때, isin( )을 활용하면 효율적인 코딩이 가능하다.
in 가이던스 on SQL (SQL) 데이터 그룹핑하기
우리는 그룹핑을 통해 데이터를 요약할 수 있다.
SQL은 GROUP BY절을 통해 데이터 그룹핑을 지원한다.
HAVING 절을 이용하여 그룹핑에 조건도 추가할 수 있다.
데이터 파악에 큰 도움을 주는 데이터 그룹핑에 대해 살펴보자.
1) 그룹핑하기 : GROUP BY
2) GROUP BY절의 주요 규칙
3) 그룹 필터링 : HAVING
4) HAVING vs WHERE
1. 그룹핑하기
그룹핑은 다음과 같은 상황에서 주로 쓰인다.
- 레코드가 종류별로 몇개가 있는지 세고 싶을 때.
- 레코드의 총합을 종류별로 알고 싶을 때.
- 레코드를 종류별로 집계하고, 조건에 따라 필터링하고 싶을 때.
SELECT 문에서 GROUP BY 절을 사용하여 그룹을 생성할 수 있다.
SELECT
vend_id
, COUNT(*) AS num_prods
FROM Products
GROUP BY vend_id
;
위의 구문은 GROUP BY 절을 사용한 예시이다.
vend_id별로 그룹핑하고, 그룹별로 레코드의 개수를 출력했다.
(그룹 계산 함수로 COUNT 함수 사용)
2. GROUP BY 절의 주요 규칙
GROUP BY절의 주요 규칙은 다음과 같다.
GROUP BY 절은 원하는 만큼의 열을 써서, 중첩 그룹을 만들 수 있다.
GROUP BY 절은 WHERE 절 뒤에, 그리고 ORDER BY 절 앞에 와야 한다.
- ORDER BY절은 항상 구문 마지막에 사용하자
- GROUP BY절은 데이터 정렬이 안될 때도 많다.
따라서 정렬을 원한다면 ORDER BY를 이용하자.
3. 그룹 필터링 : HAVING
SQL은 데이터를 그룹핑하는 것 뿐만 아니라,
그룹 필터링도 가능하게 해준다.
대표적인 예로 다음과 같은 상황이 있다.
- 최소 3번 이상 주문한 고객 리스트.
- 총 주문금액이 30000원 이상인 고객 리스트
그룹 필터링은 HAVING 절을 이용한다.
HAVING절의 문법은 WHERE절의 문법과 동일하다.
따라서, HAVING 절은 연산자나 연산키워드를 포함하여 사용하면 된다.
| 연산자 | 설명 |
|---|
| = | 같다 |
| <> | 같지 않다. |
| != | 같지 않다. |
| < | ~ 보다 작다 |
| <= | ~ 이하 이다. |
| !< | ~ 보다 작지 않다. |
| > | ~ 보다 크다 |
| >= | ~이상 이다. |
| !> | ~ 보다 크지 않다. |
| BETWEEN | 두 개의 특정한 값 사이 |
| IS NULL | 값이 NULL 이다. |
GROUP BY와 HAVING 절을 이용하여
최소 3번 이상 주문한 고객 리스트를 뽑아보는 구문은 아래와 같다.
SELECT cust_id, COUNT(*) AS orders
FROM Orders
GROUP BY cust_id
HAVING COUNT(*) >= 2;
4. HAVING vs WHERE
앞서 살펴본 것처럼, >HAVING절과 WHERE절은 데이터를 필터링할 때 사용한다.
그렇다면, 이 둘의 차이는 무엇일까?
두 절의 차이는 WHERE절은 데이터가 그룹핑되기 전에 필터링하고,
HAVING 절은 데이터가 그룹핑된 후에 필터링한다는 점이다.
WHERE 절에서 필터링되어 제거된 행은 그룹에 포함되지 않는다.
WHERE절과 HAVING절을 동시에 사용하여 더 세부적인 필터링을 할 수 있다.
예를 들어, 지난 1년동안 두 번 이상 주문한 적이 있는 고객만을 뽑아내고 싶다고 하자.
이 경우, WHERE절로 지난 1년 동안 주문했던 고객을 필터링하고,
그 다음 , HAVING 절을 이용하여 결과에서 두 번 이상 주문한 고객을 필터링하면 된다.
구문은 다음과 같다.
SELECT
vend_id
, COUNT(*) AS num_prods
FROM Products
WHERE 1=1
AND prod_price >= 4
GROUP BY vend_id
HAVING COUNT(*) >= 2;
대다수 DBMS에서 GROUP BY가 명시되지 않는다면,
HAVING절과 WHERE 절은 똑같이 처리한다.
하지만 디버깅과 업무효율화를 위해,
이 둘을 꼭 구별하여 사용하자.
- GROUP BY 집계 전 필터링 : WHERE
- GROUP BY 집계 후 필터링 : HAVING
(python) json 파일을 데이터프레임으로 만들기
1. Json이란?
1-1 Json 의 정의
json은 JavaScript Object Notation의 약자로써 자료를 주고 받을 때 주로 사용하는 파일형식이다.
약자에서 알 수 있듯이, json은 자바스크립트에서 파생되었다.
따라서 json은 자바스크립트 구문형식을 따른다.
1-2 . Json의 특징 ( 장점 )
- 특정 프로그래밍 언어, 플랫폼에 종속적이지 않다.
- 따라서 다양한 프로그래밍 언어에서 사용 가능하다.
- 서로 다른 시스템과 객체를 교환할 때 유용하다.
- 텍스트 형식으로 되어 있어, 사람과 기계 모두 파일을 읽고 쓰기 편하다.
2. Json을 판다스 데이터프레임으로 불러오기.
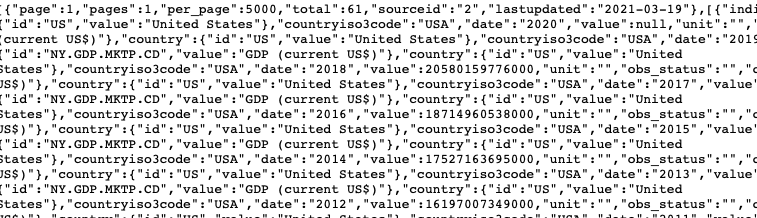
미국 GDP 정보가 저장된 json파일이 로컬 디렉토리에 있다.
이 파일을 판다스를 통해 데이터프레임으로 변환해보자.
(크롤링을 통해 웹에 저장된 json파일을 불러오는 경우 , urlopen 모듈을 이용하면 된다.)
import pandas as pd # pandas 모듈 로드
import json # json 모듈 로드
우선 pandas와 json 모듈을 임포트한다.
json_file_path="./NY.GDP.MKTP.CD.json" # 파일로드 (파일명 : NY.GDP.MKTP.CD.json )
with open(json_file_path,'r') as j:
contents=json.loads(j.read()) # open : r - 읽기모드, w-쓰기모드, a-추가모드
위와 같이 json 파일을 로드한다.
json.loads( )로 파일을 불러올 경우, 아래 그림과 같이 오류가 발생할 수도 있다.
따라서 위 구문으로 json 파일을 로딩하자.
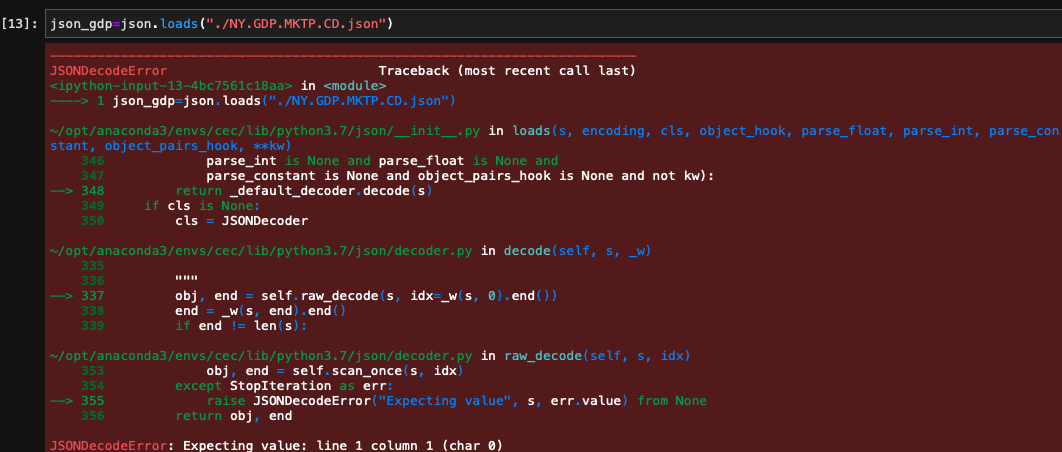
참고)
Expecting value : line 1 column 1 (char 0) 에러 발생이유
1) 인코딩 에러
2) 빈 문자열이 삽입되어 있을 경우.
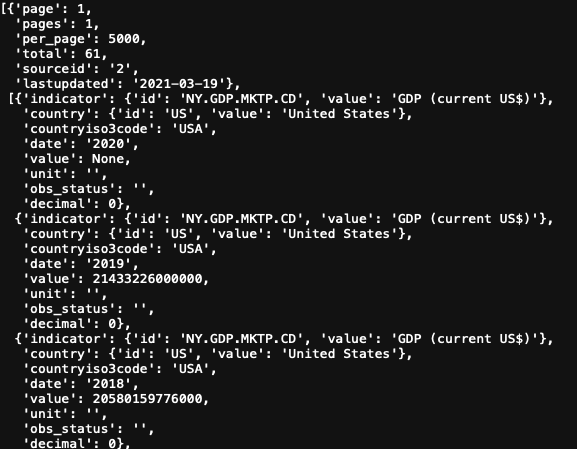
contents 객체에 json 데이터가 저장되었다.

contents 객체의 구조는 위 그림과 같다.
2번 리스트에 저장된 정보를 데이터프레임으로 만들것이다.
우선 2번 리스트에 저장된 데이터를 확인해보자.

데이터가 딕셔너리 형태로 저장되어 있다.
key값을 칼럼으로, value를 레코드로 사용할 것이다.
이를 위해 3단계의 과정을 거치면 된다.
- key와 같은 이름을 가진 빈 리스트를 만들기.
- for문과 인덱싱을 이용하여 각 리스트에 value 집어넣기.
- pd.DataFrame( {칼럼명 : 리스트} ) 이용.
date=[]
value=[]
unit=[]
obs_status=[]
decimal=[]
for i in range(len(contents[1])):
date.append(contents[1][i]["date"])
value.append(contents[1][i]["value"])
unit.append(contents[1][i]["unit"])
obs_status.append(contents[1][i]["obs_status"])
decimal.append(contents[1][i]["decimal"])
USA_GDP=pd.DataFrame({"date":date,
"value":value,
"unit":unit,
"obs_status":obs_status,
"decimal":decimal})
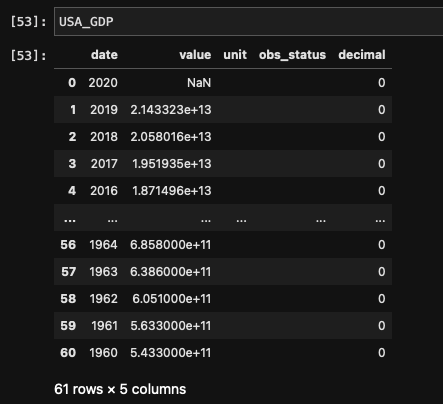
정상적으로 데이터프레임이 출력되었다.
in 가이던스 on SQL (SQL) 칼럼 연결하기 , 공백제거하기.
(SQL) 칼럼 연결하기 (CONCAT ), 공백 제거하기 ( TRIM, RTRIM, LTRIM )
회사명과 회사 위치를 함께 출력하고 싶지만, 두 정보가 서로 다른 테이블 열에 저장되어 있다.
시,도, 우편번호는 서로 다른 열에 저장되어 있지만, 배송지 주소를 인쇄하는 응용 프로그램에서는 하나의 필드로 가져와야 한다.
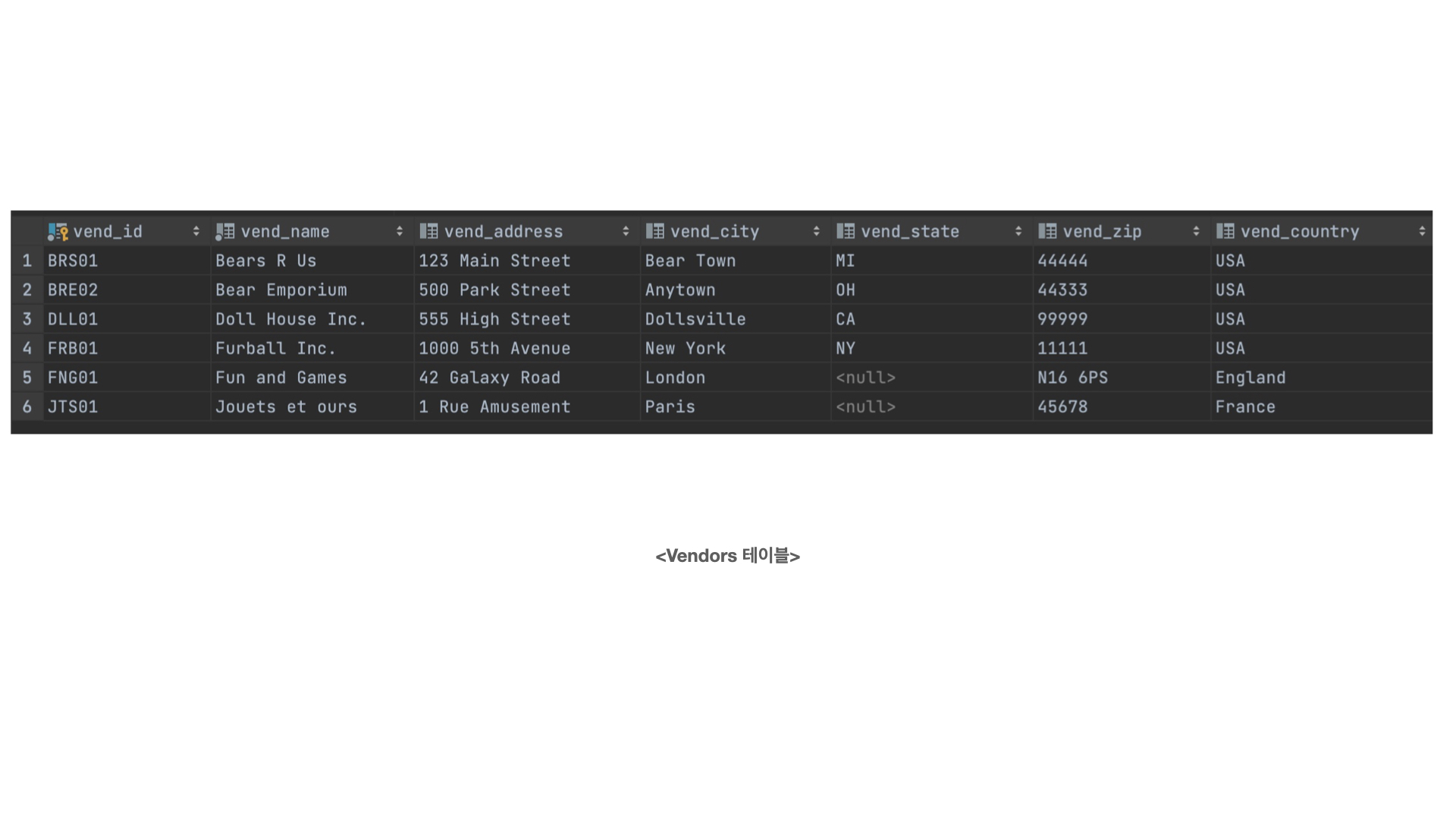
위 두 상황을 해결하기 위해서는 칼럼을 서로 연결해줘야 한다.
칼럼을 연결할 때 사용하는 함수인 Concat, || 에 대해 알아보자.
추가로, 칼럼의 공백을 제거해주는 함수인 TRIM에 대해서도 살펴보자.
✋🏾 <손에 잡히는 10분 SQL _ 인사이트> 교재를 참고해 작성한 포스팅입니다.
✋🏾 샘플데이터 다운로드 링크
1. 칼럼 연결하기 : CONCAT, ||
칼럼을 연결하는 문법은 사용하는 DBMS에 따라 다르다.
MYSQL과 MariaDB의 경우, CONCAT 함수를 이용하여 칼럼을 연결해준다.
SELECT CONCAT(vend_name,'(' , vend_country,')') AS vend_total
FROM Vendors
CONTCAT함수는 괄호안에, 연결하고자 하는 칼럼, 문자를 넣어주면 된다.
위 코드의 경우 , vend_name 칼럼과 vend_country 칼럼을 연결해준다.
추가로, 소괄호를 함수안에 삽입해 vend_country를 괄호로 감싼 것을 알 수 있다.
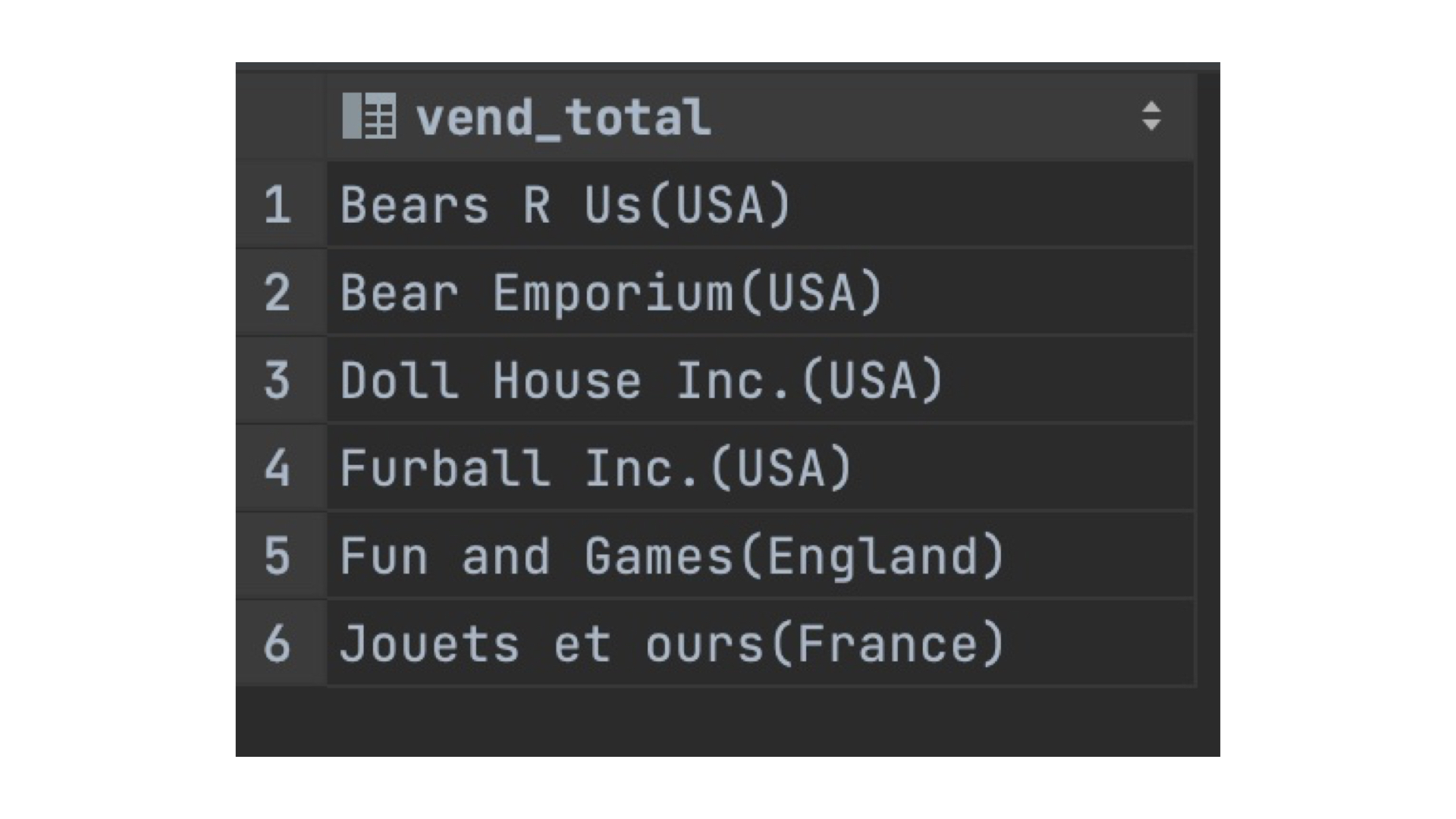
위 표와 같이 vend_name, vend_country과 연결되어 출력된다.
PostgreSql은 칼럼을 연결하기 위해 || 문법을 사용한다.
SELECT vend_name || '(' || vend_country || ')' AS vend_total
FROM Vendors
연결하고자 하는 대상 사이에 || 를 넣어주면 된다.
( CONCAT 함수보다 더 간단하고 직관적인 느낌이다)
2. 공백제거하기 : TRIM, RTRIM, LTRIM
칼럼을 서로 연결하다 보면 공백문자가 사이에 채워져 있는 경우가 많다.
연결하자하는 레코드 자체에 공백이 포함되어 있어 나타나는 현상이다.
대부분의 DBMS는 열 길이에 맞춰 텍스트를 저장하기 때문에
공백도 하나의 문자로 취급한다.
그러나 문제는 공백은 눈에 잘 띄지 않는다는 점이다.
따라서,공백을 고려하지 않고 데이터를 처리한다면
향후에 데이터 검색이나 계산시 문제가 발생할 수 있다.
다행히도 많은 DBMS가 공백제거 함수를 제공한다.
TRIM ( ) , RTRIM( ) , LTRIM ( ) 함수를 이용하면 레코드의
공백을 제거 할 수 있다.
함수명에서 눈치챈 사람도 있겠지만, 세 함수의 차이는 아래와 같다.
TRIM ( ) : 양쪽에 있는 공백 제거
LTRIM ( ) : 왼쪽에 있는 공백 제거
RTRIM( ) : 오른쪽에 있는 공백 제거
다음 코드는 공백을 제거하여 칼럼을 연결하는 코드이다.
SELECT CONCAT(RTRIM(vend_name),'(',RTRIM(vend_country),')')
FROM Vendors
ORDER BY vend_name; -- MYSQL
SELECT RTRIM(vend_name) || '(' || RTRIM(vend_country) || ')'
FROM Vendors
ORDER BY vend_name; -- Postgresql
Pagination
