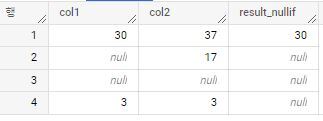
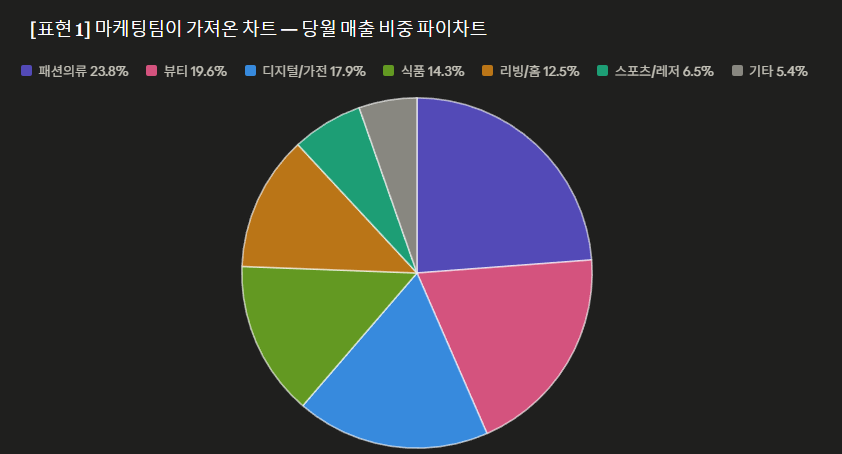
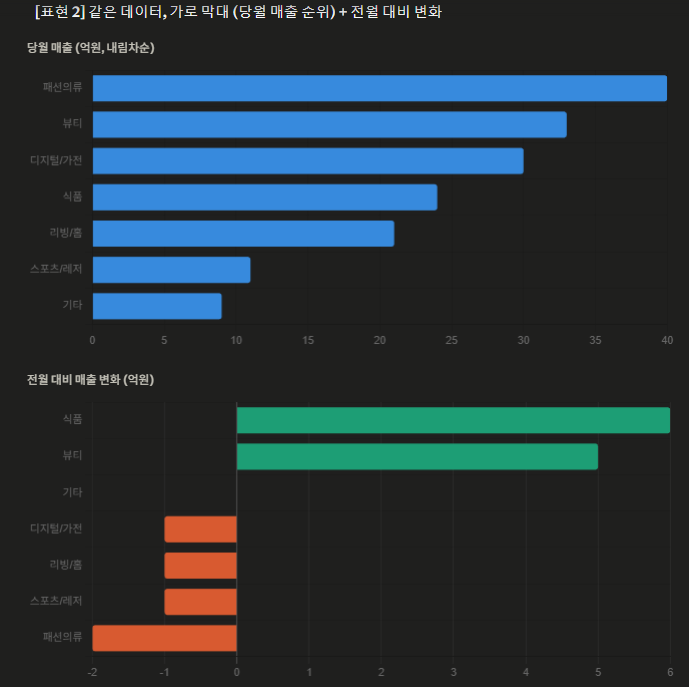
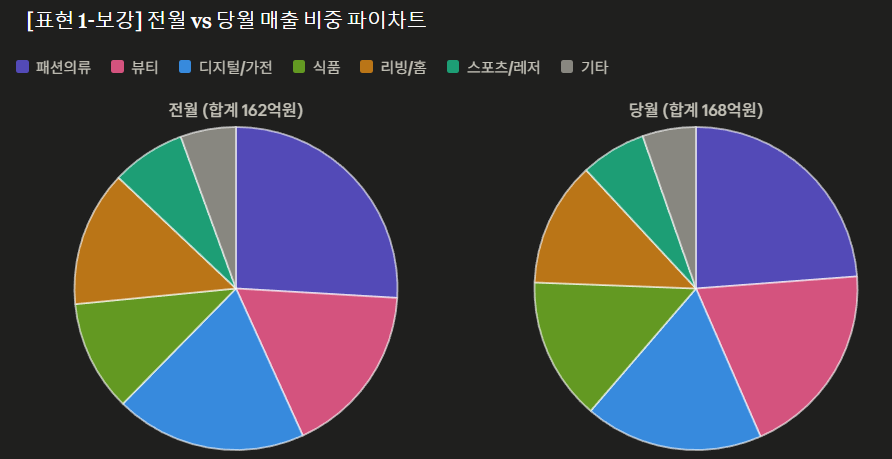
expr1과 expr2가 값이 같으면, null을 반환하고 그렇지 않으면 expr1을 반환한다.
expr1과 expr2는 같은 상위 데이터 타입에 속해야하며, 비교 가능해야 한다.
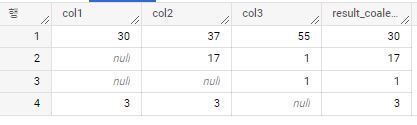
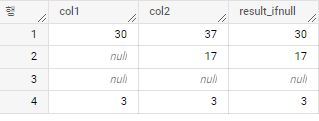
IFNULL(expr1, expr2)
expr1이 null이면 expr2를 반환한다. 그렇지 않으면 expr1을 반환한다.
expr1과 expr2에는 모든 데이터 타입이 입력될 수 있다.
COALESCE(expr1,expr2)와 같은 표현이다.
2. 예시
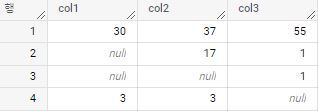
예시 데이터셋은 아래와 같다.
-- 예시 데이터 셋 제작 코드 WITHex_tableAS(SELECT30AScol1,37AScol2,55AScol3UNIONALLSELECTnullAScol1,17AScol2,1AScol3UNIONALLSELECTnullAScol1,nullAScol2,1AScol3UNIONALLSELECT3AScol1,3AScol2,nullAScol3)SELECTco11,co12,col3FROMex_table;
위 예시 데이터에 null과 관련된 조건식( coalesce,nullif,ifnull)을 넣고 결과를 비교해보자 출력 결과는 테이블 맨 우측에 위치한 result 칼럼에서 확인할 수 있다.
/*
nullif 예시
*/WITHex_tableAS(SELECT30AScol1,37AScol2,55AScol3UNIONALLSELECTnullAScol1,17AScol2,1AScol3UNIONALLSELECTnullAScol1,nullAScol2,1AScol3UNIONALLSELECT3AScol1,2AScol2,nullAScol3)SELECTcol1,col2,nullif(col1,col2)asresult_nullif-- nullif는 expr 총 2개만 비교 가능FROMex_table
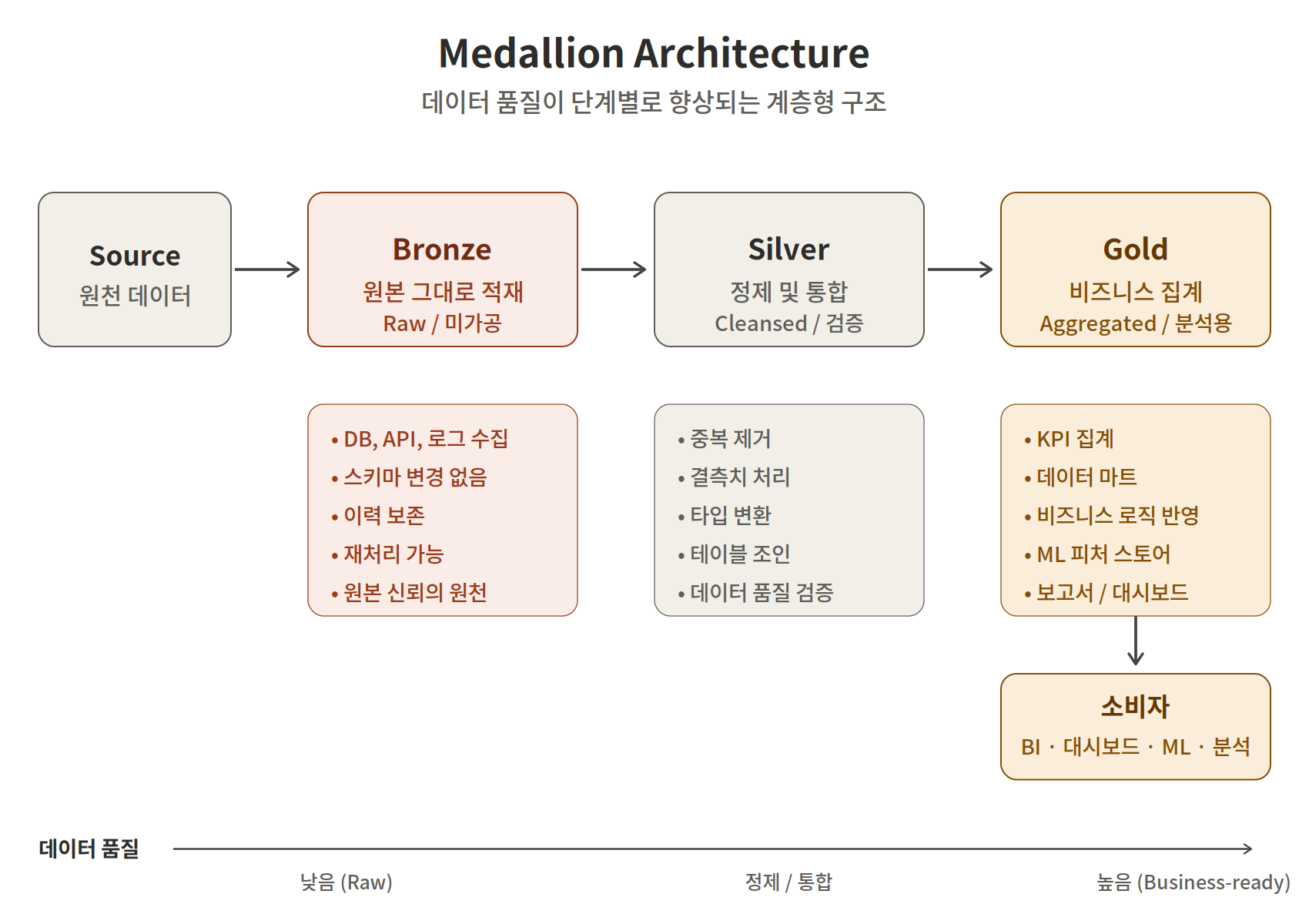
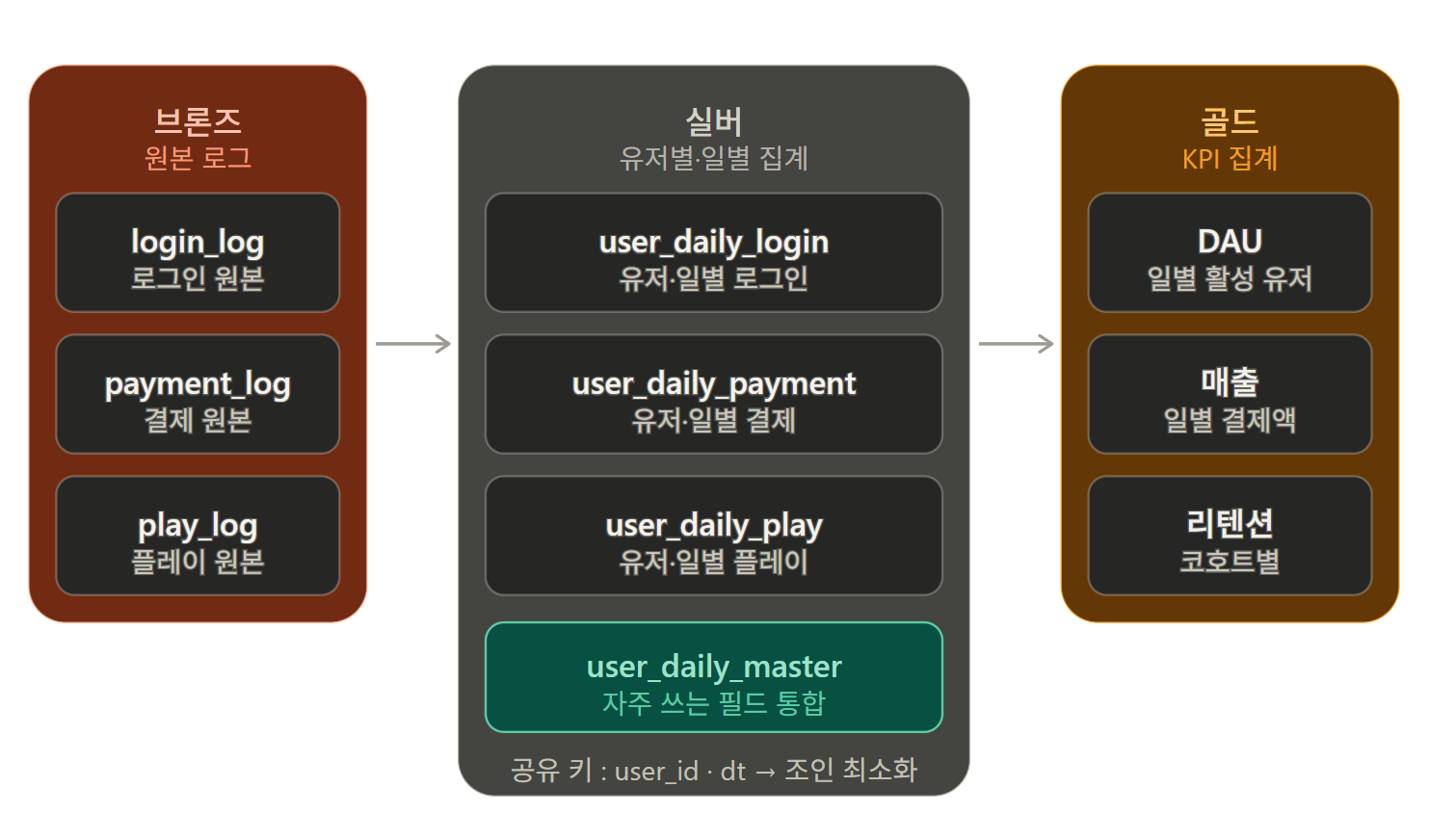
메달리온 아키텍처는 데이터 마트를 점진적인 3개의 계층으로 나눠서 구축하는 방식을 말한다. 각 계층이 연쇄적으로 연결된 형태라 관리가 용이하다는 장점이 있다.
스포츠 경기에서 성적에 따라 메달을 상으로 주고 그 등급을 브론즈,실버,골드 3개의 계층으로 나누는데 이 체계에 빗대 메달리온 아키텍처라고 부른다. 짐작하다시피 Bronze, Silver, Gold 계층이다. Bronze → Silver → Gold 로 연결되어있다.
Bronze를 이용해서 Silver 테이블을 구축하고 Silver 테이블을 이용해서 Gold 테이블을 만든다고 보면 된다. 일반적으로 Bronze는 원본 데이터, Silver는 정제 데이터, Gold는 최종 집계 형태를 띈다
Bronze : 원본 데이터를 그대로 저장. 데이터의 형태를 변경하지 않고 나중에 문제가 생겼을때 추적할 수 있는 보관소 역할을 한다.
Silver : 브론즈 데이터를 분석 가능한 형태로 다듬는 단계. 중복 제거, 결측치 처리, 타입 변환 , 필터링등으로 정제하여 데이터 분석에 적합하도록 품질을 높인 상태를 말한다. 이 시점부터 데이터 품질이 어느 정도 보장이 되며 분석가가 탐색용으로 가장 많이 참조하는 계층이기도 하다.
Gold : 비즈니스 요구사항에 맞춰 최종 가공된 데이터를 만드는 단계로 최종 사용자가 쓸수있는 형태로 집계 , 요약된 데이터가 모인 단계다. 예를 들어 지역별 월매출, 고객 세그먼트별 이탈률 같은 비즈니스 지표가 이 단계에 위치한다.
메달리온 아키텍처의 장점
메달리온 아키텍처의 장점은 크게 2가지를 뽑을 수 있다.
관리가 용이하다.
연쇄적 구조라 파이프라인 관리가 용이하다.
직관적인 구조라 테이블 명세서에 정리하기 편해 구조 파악이 쉽다.
지표 리소스를 줄일 수 있다.
BI툴을 통해 지표 제작시 추출할때마다 원본을 집계하지않고 바로 Gold 테이블을 이용하면 되기때문에 리소스를 줄일 수 있다.
Gold 테이블을 바라보면 배치 처리할때 한번만 집계하면 된다.
메달리온 아키텍처 활용 Tip
Silver 단계를 유저별 집계 테이블로 구성하여 활용도를 높이는 것을 추천한다. 특히 아래 세 항목을 고려하는것을 추천한다.
브론즈 : 원본 → 실버 : 유저별 집계 → 골드 : KPI 집계로 구현
실버 테이블간 조인이 될수있게 키값을 공유하도록 구성
특히 실버 테이블중에서 활용이 잦은 필드들을 모아놓은 마스터 실버 테이블을 만들어서 분석시 조인 최소화. ( 많은 조인은 쿼리 작성시 부담이 됨.)
실버를 유저별 일별 집계 테이블로 구성했을때 보는 관점에 따라서 골드로 볼수도 있다. 편의상 3단 구조이기 때문에 실버로 설명했지만 만약 정제 과정을 깊게 거쳐야한다면 골드를 2단계로 나눴다고 봐도 된다. 포인트는 유저별,일별 집계 테이블이 필요하다는 것이다.
깊이있는 데이터 분석을 위해서는 유저별로 쪼개서 보는 것 (드릴다운) 이 꼭 필요하다.
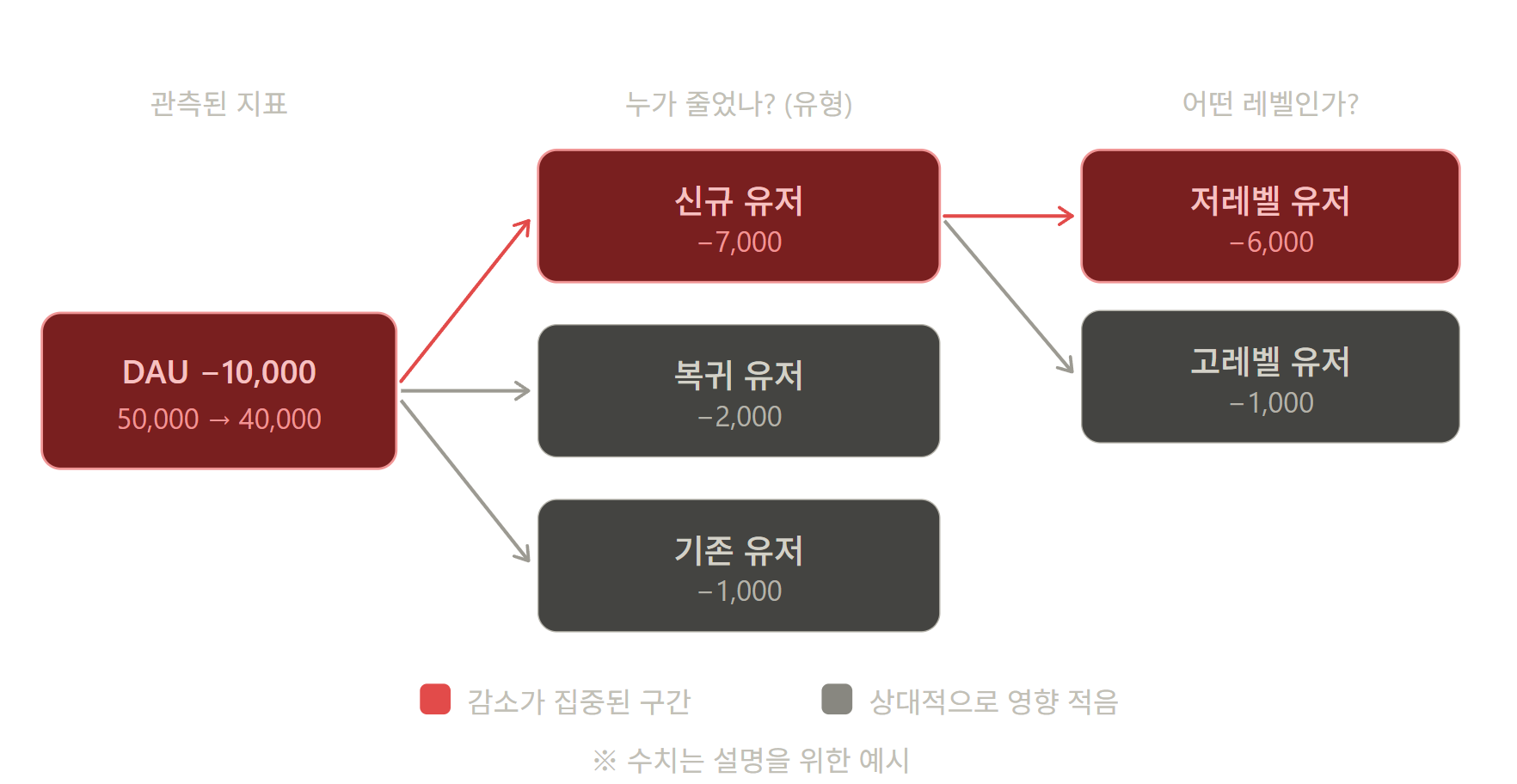
예를 들어 DAU가 50,000명에서 40,000명으로 감소했다고하자.이 지표를 보고 단순히 10,000명 감소했으니 위기다에서 끝나는게 아니라 감소한 DAU 10,000명이 어떤 유저인지? 신규 유저가 감소한것인지 , 복귀 유저가 감소한 것인지 그리고 그중에서 고레벨 유저가 감소한 것인지 저레벨 유저가 감소한것인지등 다각도로 데이터를 뜯어볼수있다.
이렇게 얼마나 상세하게 뜯어보느냐에 따라 현황 파악이 달라지며 대응 방안이 달라진다.
결국 데이터분석에는 드릴다운 분석이 꼭 필요하고 이를 효율적으로 하기 위해 유저별, 집계 테이블을 구축한다고 보면 된다. 특히 이는 점점 사용이 많아지고 있는 데이터분석 AI Agent의 답변 정확성을 올리고 효과를 극대화하는데에도 도움이 된다.
AI Agent가 최종 요약 집계된 테이블만 사용할 수 있다면 드릴다운 분석을 할 수 없고 이런상황임에도 답변 결과를 내야하기때문에 잘못된 테이블을 바라볼 가능성이 크다. 결국 할루시네이션으로 이어질수있다. Silver 테이블을 활용함으로써 이를 보완할 수 있다.
AI Agent 활용은 이제 필수인 시대가 되었다. 앤트로픽의 Claude, 오픈 AI의 Chatgpt, 구글의 Gemini처럼 다양한 AI Agent들이 서비스되고 있다. AI Agent가 일상생활에 깊게 스며들수록 이 Agent들을 어떻게 하면 잘쓸수있을지에 대한 고민도 깊어지고 있다.
1~2년전만에 해도 질문을 어떻게 하면 좋은 답변을 받을 수 있는지에 대해서 많이 나왔다. 프롬프트를 어떻게 입력하면 좋을지, 어떻게 수정하면 좋을지에 대한 많은 연구가 이뤄졌다. 이를 프롬프트 엔지니어링이라고한다. 예를 들어 아래와 같다.
맥락을 전달해라
구체적으로 질문하라
원하는 결과물의 예시를 전달해라
프롬프트 엔지니어링으로 AI Agent의 답변을 개선할수있지만 이내 이 방법만으로는 아쉬움과 한계가 있음을 알 수 있다.
우선 새 대화를 할때 다시 처음부터 정보를 입력해야한다는 점에서 번거롭다. 새 대화를 할때마다 매번 컨벤션(규칙)을 설정해야하고 컨텍스트(배경지식, 맥락)를 전달해야한다. 답변의 일관성과 연속성을 보장하기 위해 많은 토큰 비용을 써야하며 무엇보다 가장 큰 문제는 … 귀찮다는 점이다
“전에 입력해뒀던 컨벤션의 형태로 답변해줬으면 좋겠는데 ? 컨텍스트를 기억해서 답변해줬으면 좋겠는데?” 이런 생각이 드는것이다.
결국 프롬프트 엔지니어링에서 더 나아가 답변의 규칙(컨벤션)과 맥락(컨텍스트)을 고정해둘수있는 장치가 필요하다고 느끼게된다. 다행히도 클로드에서 스킬과 프로젝트라는 기능을 통해 이를 구현할 수 있다.
클로드 스킬과 클로드 프로젝트는 무엇일까?
클로드 스킬과 클로드 프로젝트 모두 답변의 컨벤션(규칙)과 컨텍스트(맥락)을 미리 세팅해둘 수 있는 장치다. 그렇다면 이 두 기능의 차이는 무엇일까? 우선 클로드 스킬과 프로젝트가 무엇인지 각각 살펴보자.
클로드 스킬
사전에 작성된 지침을 기반으로 동작함. 특정 작업 유형이 감지되면 자동으로 트리거되는 구조
관련 키워드나 요청이 나오면 해당 스킬의 작성 규칙과 컨벤션을 불러옴
지침은 SKILL.md 파일에 작성된 내용을 참고하며 이 내용은 언제든 수정 가능
클로드 프로젝트
클로드 스킬과 마찬가지로 사전에 작성된 지침을 기반으로 동작함.
특정 프로젝트 공간에 컨텍스트를 설정해두고 그 프로젝트 안에서 대화할때마다 자동으로 적용되는 구조
즉, 이 프로젝트안에서는 항상 이 맥락이 적용된다
가장 큰 차이점은 스킬은 어떤 대화든 특정 작업 유형이 감지되면 트리거되는 구조이고 프로젝트는 특정 공간에서 동일한 지침을 적용한다는 점이다. 이로 인해 실질적으로 주제별로 컨텍스트 관리라는 목적은 둘 다 달성할 수 있지만 활용 방법에는 차이가 생기게 된다.
스킬
하나의 대화 안에서 여러 컨텍스트를 필요에 따라 전환.
ex) 한 대화에서 ML분석을 하다가 경영진 보고 포맷으로 전환하고 싶을때 스킬을 통해 답변을 자연스럽게 전환시킬수있음
서로 다른 프로젝트에 있는 대화이지만 같은 컨텍스트를 적용하고 싶을때 지침을 프로젝트별로 추가할 필요없이 스킬로 작업
ex) 게임 분석 프로젝트와 이커머스 분석 프로젝트에 PPT 출력 (원하는 출력형식이 지정되어있는 지침)이라는 스킬을 실행함으로서 출력 형식을 맞춤
프로젝트
동일한 지침을 공유하는 대화를 아카이빙할 수 있다. 지난 대화를 찾아보기 쉬움
지침을 세분화해서 관리하기 쉬움 : UI가 직관적이며 파일 업로드가 가능
답변을 트리거하기 위한 별도의 명령어 없이 프로젝트안에서 대화는 지침이 유지됨
클로드 스킬, 클로드 프로젝트 활용 방안
클로드 스킬과 프로젝트는 서로를 완전히 대체하는 기능이라기보다는 보완적인 역할로 보는게 좋으며 아래와 같이 조합하여 사용할 수 있다.
첫 구매 전환 단계 개선이 튜토리얼 완료 단계 개선보다 더 많은 첫 구매를 발생시킨다. 이렇게 보면 첫 구매 전환 단계 개선이 우선적으로 필요하다고 생각할 수 있다.
다만 매출과 튜토리얼의 특성을 봐야한다. 튜토리얼은 누구나 거쳐야하는 과정이고 다음 단계로 넘어가지않으면 플레이 자체를 안해버리는 순수 이탈이다.
반면 구매는 나중에 다시 기회가 있는 행동이라 첫 구매 실패가 곧바로 이탈로 연결되지않을 수 있다. 즉 튜토리얼은 유저층을 잡을수있는 기회가 한번뿐인 단계이고 첫 구매는 다음에 다시 기회가 있는 단계이다.
미래 결제 가능성과 향후 트래픽까지 같이 고려했을때 LTV 효과는 튜토리얼 개선이 첫구매 개선보다 더 높을 가능성이 크다. 따라서 튜토리얼 개선이 우선적이라고 판단한다.
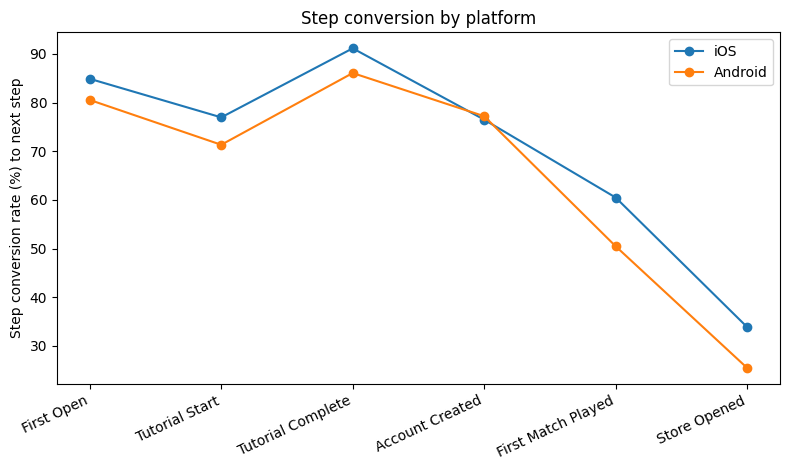
Q2. Android에서 Store-> Purchase 전환이 특히 낮은 이유를 가설로 써보자.
A2. Android와 ios의 두 플랫폼의 차이점 때문에 전환율이 달랐다고 예상할 수 있다. Android가 ios보다 약 10%p 적은 전환율을 보인다. 두 플랫폼의 차이점으로는 다음 2가지를 예상할 수 있다.
( 이용자층 ) android는 일반적으로 ios보다 구매력이 낮은 유저층의 비율이 더 높다. 구매력이 낮다고 판단할 수 있는 저가 단말을 사용하는 유저들의 비율이 높고 작업장 운영을 위한 단말기로 사용하는 경우도 많다. (일반적으로 작업장 계정은 결제를 하지않는다)
만약 패키지 상품의 가격대가 전반적으로 높다면 구매력이 낮은 유저들이 쉽게 지갑을 열지않았을 것이고 이로인해 android에서 더 낮은 결제전환율을 보였음을 예상할 수 있다. 이 케이스라면 플랫폼 전체 유저를 모수로 삼지말고 모수에 보정을 가해서 구매력이 있는 유저들을 한정하고 그 안에서 전환율을 비교하는 것이 정확한 진단을 내릴 수 있을 것이다.
( 결제 모듈 연동 ) android에 탑재된 결제 모듈이 ios에 탑재된 모듈보다 결제 절차가 복잡할 경우 이용자들은 구매에 불편함을 느낄 수 있다. 또 모듈 차이로 지원하는 결제 수단이 다를 수 있다. ex) 카카오페이는 ios에서는 되나 android에서는 지원 안함.
( 결제 실패/지연 ) android 단말기에서 결제창 진입은 했는데 구매 완료 이벤트 (purchase_success)가 안찍히는 케이스가 많을 수 있다. purchase_fail_reason, error_code, latency, crash_before_success 같이 원인을 확인할 수 있는 이벤트를 심어서 어느 구간에서 꺾이는지 확인하면 될 것이다.
Q3. Store Opened 이벤트 정의가 너무 넓으면 생기는 문제는? (퍼널 해석이 어떻게 왜곡될까)
A3. 퍼널 분석은 일방향의 연속된 단계하에서 다음 단계로 넘어갈때 유저들이 얼마나 남아있는지를 볼 수 있는 분석이다. 유저들이 어느 단계에서 다음 단계로 넘어갈때 어려워하는지 알 수 있다.
퍼널 분석에서 단계의 정의가 너무 넓으면 유저가 정확히 어느 지점에서 어려워하는지 특정하기 어려워진다. 예를 들어 store opened라는 이벤트가 있다고 가정하자. 1일내 첫 접속인지,2일내 첫 접속인지 아니면 로그인하고 첫번째 방문인지 아니면 store를 방문할때마다인지등 store opened가 정의가 너무 넓다면 유저가 어려워하는 구간이 정확히 어떤 지점인지 알기 어렵다.
요약하자면 이벤트 정의가 넓으면 아래 케이스들처럼 어느 지점이 문제인지 확인이 어렵다.
이벤트 중복 (재방문)으로 분모가 과집계 되거나 반대로 유니크 처리로 정확한 분석을 할 수 없음
store opened가 방문할 때마다 찍히면 세션 기반/유저 기반 집계에 따라 숫자가 흔들림
유니크로 유저수를 처리해도 첫 오픈인지 N번째 오픈인지 섞이면 인사이트가 흐려짐
윈도우 구간 불일치 (시간 불일치)
Store Opened는 D7까지 포함인데 Purchase는 D1만 보면 스토어는 열었는데 구매가 없다가 과장되어 보일 수 있음
최종 보고서
1. 분석 대상
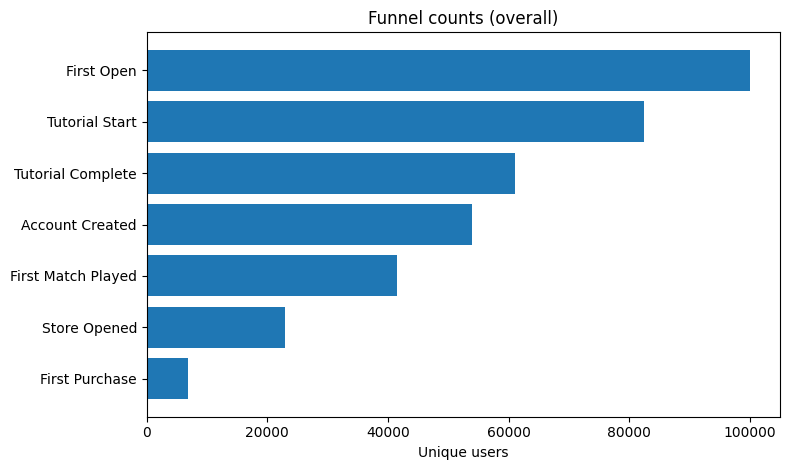
대상: 신규 유저 7일 코호트(샘플 데이터)
퍼널: First Open → Tutorial Start → Tutorial Complete → Account Created → First Match Played → Store Opened → First Purchase
2. 현황
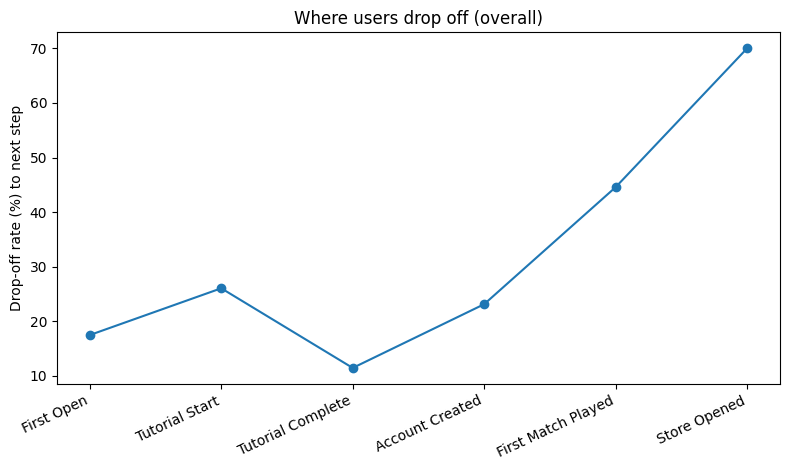
핵심 병목(상대 이탈 1위): Store Opened → First Purchase
이탈 70.0% (전환 30.0%)
플랫폼: iOS 33.9%, Android 25.5%
최대 손실(절대 이탈 1위): Tutorial Start → Tutorial Complete
-21,500명 (이탈 26.1%)
3. 액션 플랜
튜토리얼(절대 이탈 1위)을 1차 개선 대상으로 두되, Store→Purchase(상대 이탈 1위)는 결제 직전 마찰/오류 가능성이 커서 병행 점검 권장.